 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
移動平均は、 時系列近傍法 の基礎モデルとしてではなく、ノイズを除去する方法としての方が、よく知られているようです。 このページは前者の使い方についてですが、後者の使い方は、 移動分析 のページで説明しています。
ホワイトノイズモデルは、過去のデータの全部を使って平均値を計算して、予測値にします。 ランダムウォークモデルは、直前のデータだけを使って、予測値にします。
移動平均モデルは、これらの中間で、例えば、3ステップ前までの値の平均値を計算して、予測値にします。
下のデータは、最高気温のデータです。7日までのデータがあり、8日の最高気温を予測する問題を考えます。
気温の場合は、天気にも左右されるので、前日だけではなく、直近の数日のことを考えた方が良さそうですが、このような考え方は、移動平均モデルの考え方です。
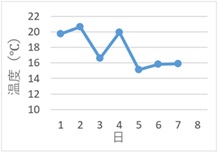
ベースになる値がゆっくりと変化していて、観測しているのがベースの値に誤差が加わったものの場合、 直前の1つの観測値だけを見るよりも、直近の複数の観測値の平均値を見た方が、ベースの値を精確に推定できます。 移動平均モデルは、このような場合に適しています。
ちなみに、ホワイトノイズモデルは、ベースになる値は変化していないことを前提としたモデルです。 ランダムウォークモデルは、ベースになる値が頻繁に変化していることを前提としたモデルです。
直近の3個のデータで計算するのなら、n番目の移動平均は、以下になります。
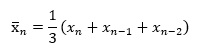
予測モデルの式は、以下のようになります。
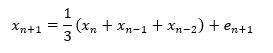
3個のデータの移動平均は、3個のデータの合計を、3で割ります。
その式を変形すると、下記のようにもなります。
「それぞれのデータに、1/3をかける」という式になっています。
1/3が3個あるので、合計は1です。
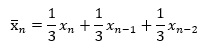
この変形を一般化すると、下記になります。
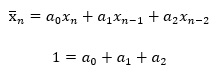
この変形をすると、例えば、「a0 = 0.4、a1 = 0.3、a2 = 0.2にして、直近のデータを重視する」といったモデルになります。 このようなモデルを、「重み付き移動平均」と言います。
指数平滑法、ARモデル、MAモデルは、重み付き移動平均を、さらに発展させた方法になっています。
指数平滑法 は、「直近ほど重視」と「多くのデータを使う」ということを実現する方法です。 「合計が1」という制約は使います。
ARモデル は、「合計が1」という制約も外して、係数を自由に設定できるようにしたモデルです。
MAモデル は、観測しているデータ重み付き移動平均ではなく、観測していないデータ(誤差)についての、重み付き移動平均を想定するモデルです。
順路
 次は
自己相関モデル(ランダムウォークモデル)
次は
自己相関モデル(ランダムウォークモデル)
