 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
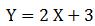
という式なら、Xの値が変わったら、Yがどのような値になるのかを
シミュレーション
するのは、簡単です。
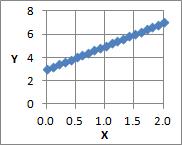
この式のXに、0から2までを0.1刻みで代入すると、下図のような結果になります。
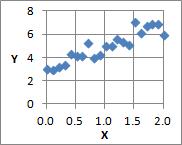
しかし、現実のデータは、下図のようになっている事が多いです。
だいたいこの式になっていても、
誤差があるので、Yは多少ばらつきます。
統計学
は、このばらつきを扱うのに優れていて、ばらつきの部分を表現するのに、
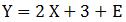
のようにして、「E」という部分を足します。
「E」は、Error(エラー:誤差)のことです。
構造方程式
では、Eを意識して扱います。
では、「Eのある式は、どうやってシミュレーションするのか?」、というのが、このページのお話になります。
統計モデル では、数式の中にEが書かれていることがありますが、象徴的です。 実際に計算して求めるのは、Eの入っていない式です。
予測のためのソフトの使い方 がありますが、Eを加味した計算結果は出ません。 そのため、例えば、「入力値がある値で一定の場合に、標準偏差がどのくらいになるのか?」といった予測はできません。
そこで、Eを加味した計算をするには、Eの部分を考慮した 数理モデル としてシミュレーションします。
Eは「誤差」なので、平均値が0の正規分布になっていると仮定する方法が手軽です。 ばらつくデータの作り方 を使って、平均値が0の正規分布になるデータをたくさん作り、それぞれをEに代入して、Yがどのような分布になるのかを見ます。
正規分布になるデータは、平均値を0と仮定するのは良いとしても、標準偏差をどうするのかが考えどころになります。 測定器の測定誤差等、実際に起きているばらつきを考慮して標準偏差は決めます。
このシミュレーションは、説明だけ読んでも、イメージがわきにくいと思いますので、 サンプルファイル も作りました。 このファイルを使うと、冒頭の2つの図のデータも作れます。
サンプルでは、Xは均等の刻みにしてあります。 実際のデータに近くするには、Xも乱数で作った方が良い事もあります。 つまり、XとEの両方が乱数で作られ、様々X(入力のばらつき)とE(出力のばらつき)の組み合わせから生み出されるYを調べることになります。 こうすると、入力のばらつきと、出力のばらつきの両方の影響を調べることができます。
ばらつきモデルのシミュレーションは、式が複雑な時に、特に役に立ちます。
Yが複雑な計算式でできているものだと、 予測区間 も複雑になりますが、シミュレーションで計算した数字をグラフにすると、予測区間がどのような分布なのかを把握できます。
誤差解析 では、Yの標準偏差はわかっていて、要因の標準偏差がどの程度なのかを推定したい事があります。
例えば、Xが2つある場合は、 それぞれのXについて、標準偏差を3通りずつ仮定してみて、 その標準偏差の組み合わせのそれぞれについて、Yの標準偏差をシミュレーションで求めてみます。 そうすれば、シミュレーションで求めたYの標準偏差と、実際の標準偏差の差が一番小さい値になる、Xの標準偏差の組み合わせではないかと、 推定できます。
順路
 次は
ばらつくデータの作り方
次は
ばらつくデータの作り方

