 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
統計モデルによる予測 のページの例は、Xの代入が1個ですし、式も簡単です。
ところが、式が複雑になると、簡単に計算できません。 筆者には、もっと複雑なモデルを使おうとして、どのようにしたら良いのかがわからなくなった経験があります。 ソフトを使ってやろうとした時に、「どうすれば?」となりました。
多変量解析 や データマイニング の一般的な解説書は、モデルの内容や、その作り方の説明になっていて、予測のための使い方は書かれていないので、 このページをまとめてみました。
ブロックをつなげるソフトとしてRapidMiner、プログラムを書くソフトとしてRを例にします。 これらを知っていれば、他のソフトでも困らないと思います。
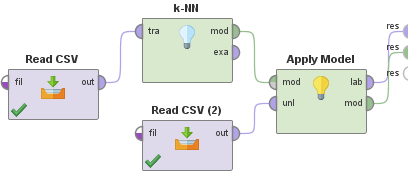 RapidMiner
の場合、図のように計算を組めばできます。
RapidMiner
の場合、図のように計算を組めばできます。
手法による結果の違い のページは、この方法で作りました。
R の使用例は下記になります。 (下記は、コピーペーストで、そのまま使えます。 この例では、Cドライブの「Rtest」というフォルダに、 「Data1.csv」という名前で学習データがあり、 「Data2.csv」という名前でテストデータが入っている事を想定しています。
また、教師データとして、「Y」という名前の変数が、学習データに入っている事を想定しています。 下記の場合は、「Y」以外のすべての変数が、モデル作成に使われるようになっています。(「.-1」とすると、そのような指定になります。)
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data1 <- read.table("Data1.csv", header=T, sep=",") # 学習データを読み込み
Data2 <- read.table("Data2.csv", header=T, sep=",") # テストデータを読み込み
lm <- lm(Y ~ ., data=Data1) # 学習データでモデルを作る。この例は、重回帰分析です。
lm1 <- predict(lm, Data1) # 学習データの予測値を作成
lm2 <- predict(lm, Data2) # テストデータの予測値を作成(学習データのモデルを使うのがポイント)
write.csv(lm1, file = "lm1.csv") # 学習データの予測値をファイルに出力
write.csv(lm2, file = "lm2.csv") # テストデータの予測値をファイルに出力
順路
 次は
現実と統計モデルとのギャップ
次は
現実と統計モデルとのギャップ
