 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
データリテラシー のページで、データをつなぐことについて、簡単に説明しています。 データがつながると、いろいろなことの関係が分析できるようになります。
このページのタイトルの「紐付け」というのは、データをつなげることを指しています。
データの紐付けは、同じデータベースの中のデータについて、キーになる項目を使って紐付ける方法が一番簡単です。 リレーショナルデータベース では、よく知られています。 また、EXCELだとvlookup関数でできます。
異種のデータを紐付ける場合は、 特徴量エンジニアリング をしてからでないと、紐付けができないことがあります。 また、特徴量エンジニアリングをすることで、分析できることが大きく広がります。
異種データの紐付けについて、このページでは、従来の解説の範囲とも合わせながら、考え方を整理してみました。
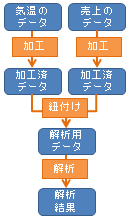
まず、このページの話の前提として、データ解析の実際の流れは、図のような感じです。 ここでは、気温と売上の関係を調べるための解析を例にしてみました。
気温のデータと、売上のデータは情報源が別だったとします。 気温は、1時間毎のデータで、売上は、1日毎のデータだったとします。
こういうデータの場合、解析で知りたい事と、データの中身を比べて、どのようにするのかを決めますが、 ここでは、気温も1日毎のデータに加工するとします。 こうすると、気温のデータと、売上のデータの紐付けができるようになります。
紐付けされたデータができれば、ここからが、いわゆるデータ解析になって、
「気温の高い日は、売上が高い」などの解析結果を出す事ができます。
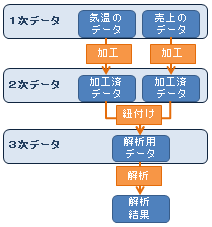
準周期データの分析
のところで、1次から3次までのデータ形式の話を書きましたが、
データの形式の呼び方は、このページの例にも当てはまります。
「 統計学 、 データマイニング 、 機械学習 、 ディープラーニング といった手法を知っていれば、データ分析ができる。」、という誤解は、よくあるようです。
しかし、これらの手法は表形式になっている状態のデータに使うと有効な手法なので、 1次データの状態で、別々の形になっているデータの両方を合わせた分析ができるようにはなっていません。
こうした分析をしたいのなら、3次データの形まで進めておく必要があります。
上記では、「気温も1日毎のデータに加工する」と、さらっと書きましたが、 「最高値、平均値、最低値、上昇速度」など、どういう形にまとめるかは検討する必要があります。 また、1時間毎のデータについて、24時間全部を集計するのか、営業時間や、朝の時間に限定するのか、といった事も検討する必要があります。
この領域の中で、特に2次データを作るあたりは、実際のデータの内容や、解析の目的で、いくらでもバリエーションがありますが、 世の中であまり話題になりません。 話題にならないのは、スマートな理論や、手順で表現できませんし、泥臭い作業も必要になる点かと思います。
「気温」や「売上」といった身近な数字であれば、どのようにデータを加工すれば良いのかは、よく考えればわかることもあります。 しかし、機械が出力するデータや、高度な測定をして得られたデータなどについては、データの意味がわからないところからスタートすることがあり、 考えればわかるようなものではないです。 調査したり、有識者に聞いたりする必要があります。
「いくらでもバリエーションがある」という点については、 「今のコンピュータなら、あらゆるパターンを出して、一番説明能力のあるパターンを採用すれば良いのではないか?」や、 「 人工知能 なら、一番良いパターンを見つけられるのではないか?」、といった意見をいただくことがあります。
しかし、ここでポイントになって来るのは、問題の範囲の「定義」や「定型化」の作業ですので、少なくとも今の人工知能で扱える話ではないと思っています。
このサイトでは、センサーデータの2次データを作る時の例として、 2次データの解析 のページがあります。 この例は、何か特別な種類のセンサーデータの話ではなく、 時系列データ全般にも使えます。
一筋縄ではいかない、ややこしい話になって来るのですが、ここを通り過ぎると分析できる内容が広がります。
順路
 次は
データの確からしさ
次は
データの確からしさ

