 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
高次元を2次元に圧縮して可視化 の方法は、一般的には、教師なし学習の方法として分類されます。
このページのタイトルにある「回帰分析系」というのは、 回帰分析 を代表として、目的変数が量的データになっている教師あり学習の方法のことです。 サポートベクターマシン や 決定木 で、目的変数が量的データになっている場合も、回帰分析系の仲間です。
回帰分析系の方法は、高次元を2次元に圧縮して可視化 の方法に応用できます。
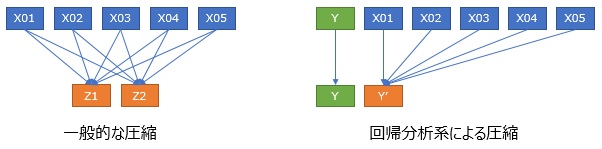
高次元を2次元に圧縮して可視化
の一般的な方法は、上図の左です。
何らかの変換をして、3個以上ある変数を2個にします。
2個(2次元)で、多次元の特徴が見れるようにします。
変換の仕方が、各手法の工夫になっています。
回帰分析系の場合は、元々ある変数の中に、Yという、ひとつだけ特別なものあります。 Yについては、何も変換はしないです。 Y以外の変数についてだけ、変換をします。
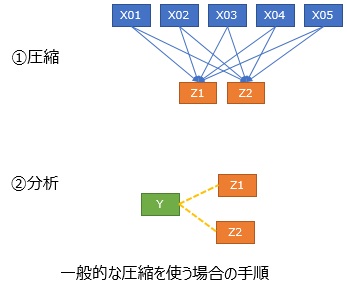
Yに相当するような変数があって、
高次元を2次元に圧縮して可視化
の方法を使う場合は、
まず、Y以外の変数について、圧縮してから、圧縮した変数とYの関係を分析する手順になります。
一方、回帰分析系で圧縮する場合は、圧縮と同時に分析ができます。
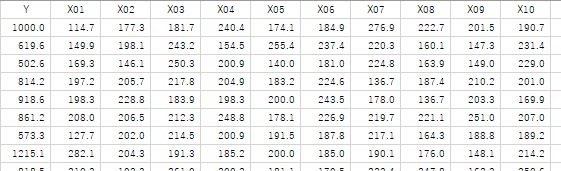
手法の比較です。
ここで使ったデータは、サンプルが100個あります。
Yという変数とX01からX10までの変数があります。
Yは、Xの2乗などから計算されています。
ただし、1行目のサンプルのYは、計算式を使っていないで、適当に入れた数(1000)になっています。
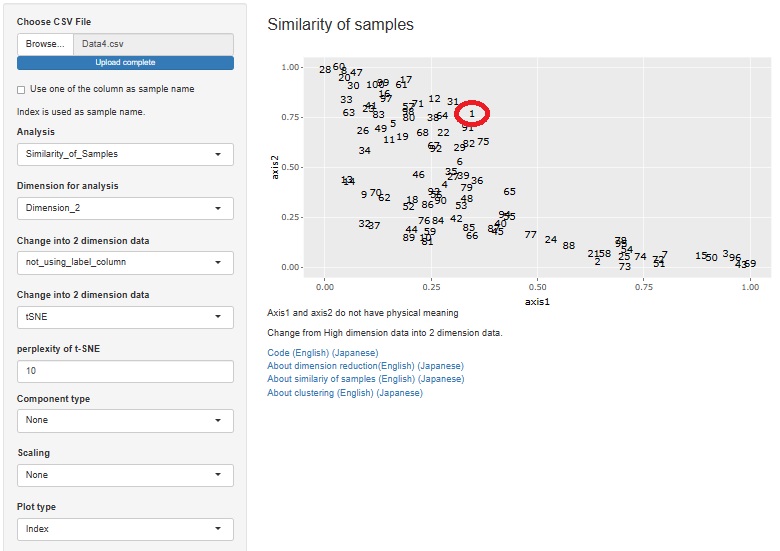
一般的な圧縮の場合として、上はt-SNEを使っています。
この例の他にも、いろいろ試しましたが、何とも言えないような結果にしかなりませんでした。
1行目のサンプルは、集団の中にいます。
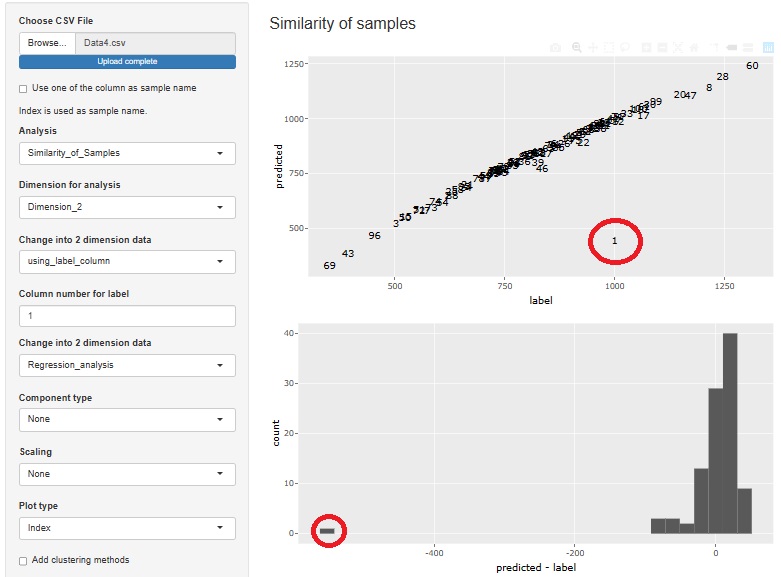
重回帰分析を使って圧縮した場合です。
1行目のサンプルが孤立しています。
散布図の下にあるヒストグラムは、残差で、 残差の外れ値 の分析の見方をしています。 一般的な圧縮の場合は、圧縮した2次元に特に意味がないのですが、回帰分析系の場合は、予測値の方は実測値に似るように計算された値なので、 両方の差にも意味があります。
高次元を2次元に圧縮して可視化 に限らず、 サンプルの類似度の分析 は、Yに相当する変数がない場合の分析方法です。
「Yに相当する変数がある場合」と「サンプルの類似度の分析」というのは、別々の場所で使われますが、 このページの場合は、一緒になっています。
回帰分析系による圧縮の方法は、Yに相当する変数があるデータについて、サンプルの類似度の分析として使うことが、使い道のひとつになります。
上の例のように、外れ値のようなサンプルを見つける方法にもなります。
残差の外れ値 を見つける方法は、回帰分析系による圧縮の姉妹版のような方法です。 YとY'の差は、残差ですが、残差を分析対象にしています。
Excelでは、回帰分析の予測値を、簡単に分析できます。 このサイトでは、 Excelによる残差の外れ値の分析 のページで、その紹介をしています。
上図がR-EDA1の使用例になります。 R-EDA1では、元の変数のYが「label」として横軸に、Y'が「predicted」として縦軸になるようにして、2次元の散布図が作られます。
上の場合は、回帰分析ですが、
モデル木
や
サポートベクター回帰
も使えます。
Rによる回帰分析系で高次元を2次元に圧縮して可視化 では、 R-EDA1に入れているコードの中心になっているものが入っています。
順路
 次は
正準相関分析で高次元を2次元に圧縮
次は
正準相関分析で高次元を2次元に圧縮
