 僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
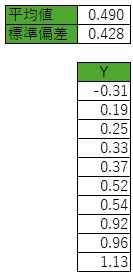
埲壓偺椺偱偼丄忋偺傛偆側10屄偺僨乕僞偑偁傝丄乽暯嬒抣偼丄侽傛傝傕戝偒偄偲尵偊傞偐丠乿傪挷傋偨偐偭偨偲偟傑偡丅
偙偺僨乕僞偺暯嬒抣偼0.490丄昗弨曃嵎偼0.428偱偡丅
o抣偺堘偄偑壓偺恾偱偡丅
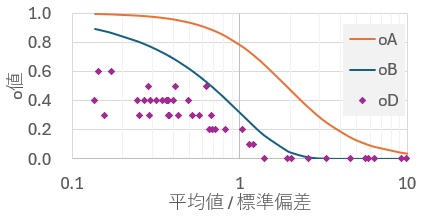
oA偲oB偵偮偄偰偼丄昗弨曃嵎偑堦掕側傜丄暯嬒抣偑彫偝偗傟偽侾偵嬤晅偒丄戝偒偗傟偽侽偵嬤晅偔惈幙傪帩偭偰偄傞偙偲偑傢偐傝傑偡丅

尦偺僨乕僞傪X1偲偄偆曄悢偵偟偰丄暯嬒抣傪堷偄偨僨乕僞X0傪嶌傝傑偡丅
X0偺暯嬒抣偼侽偵側傝傑偡丅
昗弨曃嵎偼丄曄傢傜側偄偱偡丅

僨乕僞傪堦楍偵暲傋偰丄怴偨偵X偲偄偆曄悢傪嶌傝丄X偺抣偱Y1偲Y0傪嬫暿偱偒傞傛偆偵偟傑偡丅
偙偙傑偱弨旛偱偒傞偲丄偙偙偐傜偼丄
暯嬒抣偺嵎偺専掕偺o抣A
偲婎杮揑偵摨偠偱偡丅
憡娭學悢R傪媮傔傑偡丅

=1- R1^2
忋偺椺偱偼丄o抣偼丄0.7328偵側傝傑偡丅
o抣偺怣棅嬫娫乮忋懁乯偱偡丅 憡娭學悢偺怣棅嬫娫 傪巊偄傑偡丅
=1-( ( EXP(LN( (1+R1)/(1-R1) ) -2*1.96/SQRT(n1-3) ) -1) / ( EXP(LN( (1+R1)/(1-R1) ) -2*1.96/SQRT(n1-3) ) +1) )^2
z専掕傪巊偆偲丄壓偺幃偱o抣偑媮傑傝傑偡丅
=(1 - NORM.DIST(0.49,0,0.428,TRUE)) *2
0丄0.49丄0.428偺埵抲偑堎側偭偰偄傑偡偑丄壓偺幃偱傕丄摨偠o抣偑媮傑傝傑偡丅
偙傟偼丄専掕摑寁検偵偁傜偐偠傔昗弨壔傪偡傞偐偳偆偐偑丄堘偄偵側偭偰偄傑偡丅
=(1 - NORM.DIST((0.49 - 0)/0.428,0,1,TRUE)) *2
o抣偺怣棅嬫娫偼丄 p抣偺怣棅嬫娫 偲摨條偵丄岠壥検偺怣棅嬫娫偺忋懁偲壓懁偺抣傪丄o抣偺寁嶼幃偵擖傟偰寁嶼偟傑偡丅
壓婰偼丄怣棅嬫娫偺忋懁偺媮傔曽偱偡偑丄壓懁偱傕摨條偱偡丅
EXCEL偺応崌丄椺偊偽丄壓偺幃偱o抣偺怣棅嬫娫乮忋懁乯偑媮傑傝傑偡丅n偼丄僒儞僾儖悢偱偡丅
=(1 - NORM.DIST((0.45 - 0)/0.42 - 1.96/sqrt(n),0,1,TRUE)) *2
暯嬒抣偺専掕偺o抣A偼丄娙扨偱偡丅
侽埲壓偺僨乕僞偺妱崌傪挷傋傑偡丅
偙偺椺偱偼丄10屄拞1屄側偺偱丄
o抣丂亖丂0.1 乮= 1 / 10乯
偱偡丅
暯嬒抣偺専掕偺o抣B偼丄暘晍傪壖掕偟偰寁嶼偡傞昁梫偑偁傝傑偡偑丄暯嬒抣偺専掕偺o抣A偼丄壗偱傕巊偊傑偡丅僲儞僷儔儊僩儕僢僋専掕偺堦庬偲傕尵偊傑偡丅
弴楬
 師偼
21悽婭偺丄懳墳偺偁傞暯嬒抣偺嵎偺専掕
師偼
21悽婭偺丄懳墳偺偁傞暯嬒抣偺嵎偺専掕
