このページの「分布のズレの検定」というのは、 21世紀の検定 として、筆者が考案した方法のひとつです。 他の 21世紀の検定 と同様に、世の中ですでに同じものが発表されている可能性はあるのですが、 筆者の知る限りではなさそうなので、筆者が名前を付けています。
「分布のズレの検定」は、 平均値の検定 の 21世紀の検定 版です。
対応のある検定 は、 平均値の検定 の応用なので、「分布のズレの検定」は、対応のある検定の21世紀の検定版として、応用できます。 このページでは、最初に対応のある検定の話から始め、途中から、分布のズレの検定、という順番で説明します。
対応のある検定
の復習になります。
対応のある検定
は、
平均値の差の検定
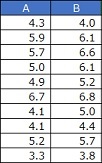
の一種で、下のようなデータがあった時に、AとBという2つのグループの、それぞれの平均値に差があるかを調べます。
その時に、データの各行は対応があるとします。
例えば、「各行は同一人物のデータ」といった場合です。
対応のある検定
では、「B-A」というように、各行の差を計算します。
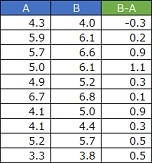
この後、 平均値の検定 をします。 BがAよりも大きければ、B-Aは0よりも大きくなるはずなので、 「B-Aの平均値は、0よりも大きいと言えるか?」という問題として扱います。
「分布のズレの検定」は、平均値の検定の代わりに使う方法です。
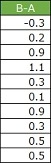
上の図のような10個のデータがあり、「0よりも大きいと言えるか?」を調べたかったとします。
平均値は0.45、標準偏差は0.42です。
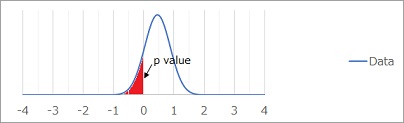
分布のズレの検定1では、赤い部分の面積を計算して、これをp値と考えます。
ここでは正規分布を仮定しています。
EXCELの場合、下の式でp値が求まります。
=NORM.DIST(-0.45,0,0.42,TRUE)
0.45と0.42という数字は、平均値と標準偏差から来ています。 上の図は、「平均値が0からどのくらいズレているか?」という問題ですが、計算式は分布の中心を0に修正するので、「-0.45」となっています。
平均値の差の検定では、「平均値の差 / 標準偏差」という数字を「効果量」と呼んで、どのくらい差があるのかの目安として使います。
分布のズレの検定1でも、効果量の考え方は役に立ちます。ここでは、 「平均値 / 標準偏差」を計算します。 例の場合は、1.1(= 0.45 / 0.42)となります。
効果量が大きい場合、差のばらつきが非常に小さいと考えられます。
分布のズレの検定2は、簡単で、0以下のデータの割合を調べます。
この例では、10個中1個なので、
0.1 (= 1 / 10)
です。
分布のズレの検定2では、
P値 = 0.1 (= 1 / 10)
と考えます。
上の例の場合、
分布のズレ検定1では、p値が0.14、
分布のズレ検定2では、p値が0.1、
で、だいたい同じ値になります。
1の方法は、分布がどうなっているのかを含めて、差があるのかを調べられます。 2の方法は、とにかくグループに差があるかどうかを調べる方法で、どのくらい差があるのかは、考慮されません。 効果量の考え方も使えないです。
1の方法は、分布を仮定して計算する必要がありますが、2の方法は、何でも使えます。ノンパラメトリック検定の一種とも言えます。
対応のある検定 のページに注意点が2つありますが、分布のズレの検定の1と2の両方とも、サンプル数に影響されない方法です。 1の方法は、外れ値の影響を受けますが、2の方法は、受けません。
対応のある検定
のページに、対応のある平均値の差の検定ではBが高いとは言えるけれども、全体的にはBが高いとは言えない例があります。
下図のような場合です。
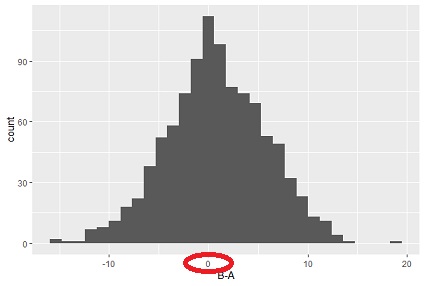
この例で、このページの方法を使うと下記になります。
分布のズレの検定1のP値 = 0.47
分布のズレの検定1の効果量 = 0.086
分布のズレの検定2のP値 = 0.43
対応のある検定 のページでは、グラフの見た目だけで、「全体的にはBが高いとは言えない」と説明していますが、定量的にはこのようになります。
対応のある検定 だけだと、「Bの方が有意に高い!対策は効果がある!」となりがちですが、 これらの分析もすると、「4割以上でAの方が低くなる」と言ったことも、定量的に示せるようになります。
何かのテーマとして、この分析を使う場合、最終的な結論は、B-Aの平均値、B-Aの範囲も踏まえて出した方が良いかと思います。
順路
 次は
正規分布の差の検定
次は
正規分布の差の検定
 Tweet
Tweet
