Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
次元削減クラスタリング分析 のRによる実施例です。
このページの前半部分についての詳しい話は、 高次元を2次元に圧縮して可視化 です。
後半部分についての詳しい話は、 クラスタリングの原因分析 です。
この例では、Cドライブの「Rtest」というフォルダに、
「Data1.csv」という名前でデータが入っている事を想定しています。
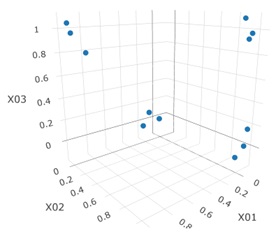
ここで使っているデータは、3次元空間に4個のグループがある場合です。
library(fastDummies)# ライブラリを読み込み
library(som) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data1 <- Data # 加工用のデータの作成
Data1$Name <- NULL # データからNameの列を消す
Data2 <- Data1
# Data2 <- dummy_cols(Data2,remove_first_dummy = FALSE,remove_selected_columns = TRUE)# ダミー変換。質的変数がある時は、#を外す
Data3 <- normalize(Data2[,1:ncol(Data2)],byrow=F)# 標準化
t-SNEを使う例です。
library(Rtsne) # ライブラリを読み込み
ts <- Rtsne(Data3, perplexity = 3) # t-SNE
Data5 <- ts$Y# 得られた2次元データの抽出
library(ggplot2) # ライブラリを読み込み#
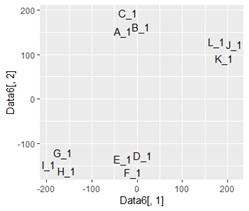
Data6 <- cbind(Data5 ,Data) # 2次元に凝縮されたデータに、元データを合体
ggplot(Data6, aes(x=Data6[,1], y=Data6[,2],label=Name)) + geom_text() # Nameを使った言葉の散布図
library(ggplot2) # ライブラリを読み込み#
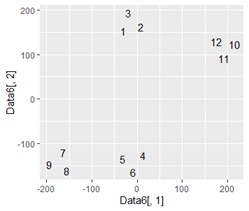
Data6 <- transform(Data5 ,Data,Index = row.names(Data)) # 2次元に凝縮されたデータ、元データ、元データの行番号を合体
ggplot(Data6, aes(x=Data6[,1], y=Data6[,2],label=Index)) + geom_text() # 行番号を使った言葉の散布図
library(ggplot2) # ライブラリを読み込み
Data6 <- transform(Data5 ,Data, Index = row.names(Data)) # 2次元に凝縮されたデータ、元データ、元データの行番号を合体
Data6$Index <- as.numeric(Data6$Index) # Indexを数値型に変換
ggplot(Data6, aes(x=Data6[,1], y=Data6[,2])) + geom_point(aes(colour=Index)) + scale_color_viridis_c(option = "D")# 行番号を使った散布図
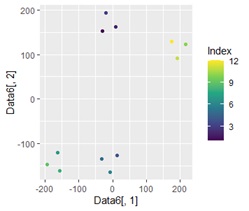
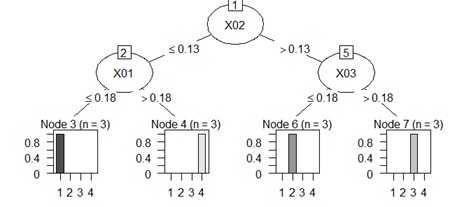
上記までで、グループが4つに分かれることがわかったので、4つのグループを作ります。
library(ggplot2) # ライブラリを読み込み
library(mclust) # ライブラリを読み込み
mc <- Mclust(Data6[,1:2],4) # 混合分布によるクラスター分析。これは4個のグループ分けの場合
clust <- mc$classification # クラスター分析の結果を抽出
clust <- as.factor(clust) # clustを文字型に変換
Data7 <- cbind(Data6 ,clust) # クラスター分析の結果とデータを合体
ggplot(Data7, aes(x=Data6[,1], y=Data6[,2])) + geom_point(aes(colour=clust)) # グループごとに色分けした散布図
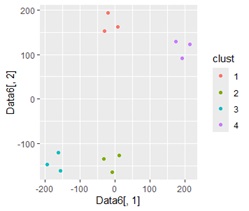
Data8 <- cbind(Data1, clust) # 分析用データの作成
# 決定木をC5.0にする場合です。
library(partykit) # ライブラリを読み込み
library(C50) # ライブラリを読み込み
for (i in 1:ncol(Data8)) {
if (class(Data8[,i]) == "character") {
Data8[,i] <- as.factor(Data8[,i])
}
if (class(Data8[,i]) == "logical") {
Data8[,i] <- as.factor(Data8[,i])
}
}
treeModel <- C5.0(clust ~ ., data = Data8)# rpartを実行
plot(as.party(treeModel)) # グラフにする。