 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
「これからはDXだ!・AIだ!」という感じで、導入を進める会社がとても多いです。
しかし、専門の部署を立ち上げたものの、軌道に乗らない会社が、非常に多いようです。 (この種のネガティブな情報は、あまり表に出ないので、「非常に多い」というのは、筆者の見聞きしている範囲からの推測です。)
筆者自身も推進する部署の経験がいくつかあります。
そこで、このページでは、思い当たる原因をまとめてみました。
また、それぞれの原因について、対策も書き出しました。
DXやAIは、「会社を成功に導くもの」、「これからは、なくてはならないもの」という説明がされます。 一方、このページでは、「必ずしも、そうではない」という話をします。
以下は、失敗する理由を説明します。 わかりにくい話なので、同じことについて、見方や言い方を変えて説明しているところもあります。
ここでは、AIの推進が失敗する理由についてです。
迷惑メールフィルター、レコメンド、画像認識、文章生成といった技術は、 私たちの生活に大きな貢献をしています。
これらの技術は、機械学習と呼ばれる技術を応用して作られた技術です。 今まで人間がやっていたことを、これらの技術で置き換えたり、 人間では不可能な量が扱えることを使って、これらの技術を使った新しいサービスを作ることで、社会に貢献しています。
ただし、この応用技術を使った仕事が、無尽蔵にある訳ではないので、どこかで仕事がなくなって来ます。
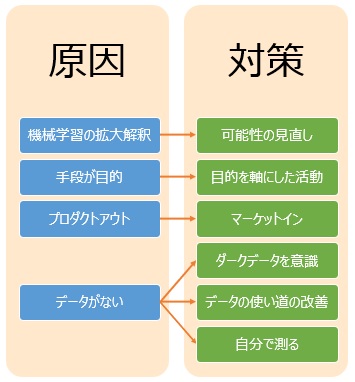
機械学習の応用技術が社会を変えていますが、それが拡大解釈されて、「機械学習は、どんなことでも人間の代わりになり、しかも、人間以上のことができる」というような理解をしている人が多いようです。
この誤解から、機械学習に大きな期待を寄せて、あらゆることへの導入を進めようとした場合は、「何に使えば良いのかがわからない」という状況になりがちです。
ここでは、DXとAIで共通する失敗する理由についてです。
方法の独り歩き でも書いていますが、何かをやるための手段(方法)なのに、手段をすること自体が目的になっていることがあります。
最初のうちは、それでも良く、「こんなことをやった!」ということが、社外へのアピールになることもあります。 しかし、会社の場合は、利益が伴わないことは続かないです。
「プロダクトアウト」というのは、買い手が欲しいかどうかを確認せずに、「欲しがるはず」という売り手だけの思いだけで、売り始めることです。商売が失敗する理由として、昔からよく言われています。 その逆が「マーケットイン」です。
「プロダクトアウトではなく、マーケットインでないとうまく行かない」ということを知っている人は多いはずですが、DXやAIは、プロダクトアウトの発想で話が進むことがよくあります。
例えば、機械学習の応用として、異常検知の技術があります。 しかし、現場の立場では、異常検知よりも、異常の原因をなくすことの方が大事です。 異常の原因がなくなるのなら、異常検知は必要がありません。 このような顧客に、異常検知を勧めるのは、プロダクトアウトになります。
ちなみに、マーケットインの話から外れますが、工場では、材料や環境が変わり続ける中で、同じ製品(正確には、同じとみなせる製品)を作り続けようとします。 その意味では、統計学的に安定した状態がなく、常に異常です。 また、安定が保たれていて、正常の状態が確立できているような場合でも、安定している要因のすべては把握していないことが多いです。 これらも、異常検知を導入しようとして、うまく行かない理由のひとつです。
DXとAIは、いずれも、データ(より正確には、「電子データ」)があることが前提になっている技術です。
「会社にはビッグデータがすでにある。だから、DXやAIが活用できる準備ができている」という説明の仕方を、時々見かけます。
しかし、大量のデータがあったとしても、それらがDXやAIの目的に合うかは、別の話です。 たいていの場合は、合わないです。
対策は、失敗の逆を考えると道筋が見えて来ます。
ただ、「言うは易し、行うは難し」で、実際に実行するのは、簡単ではないです。 (宣伝ですが、 杉原データサイエンス事務所 は、これを実行する手立てを整備して、伝える活動をしています。)
機械学習を使おうとすると、行き詰ってしまうことへの対策です。
「応用技術の種類が少ないから、行き詰まるのだ」や、「機械学習には、もっと可能性があるのだ」と考えるのなら、 機械学習の応用技術を生み出すことが、ひとつの方向性としてあります。 しかし、これを進めるには、発明家としての能力も必要なので、データサイエンスの専門家でも簡単ではありません。
もうひとつの方向性としては、機械学習や、その基礎になっている統計学にはこだわらず、「データを活用する」というように、 データサイエンスを広くとらえて行くことがあります。 「データサイエンス = 機械学習」、「データサイエンス = 統計学」という理解をしている人が多いですが、 機械学習や統計学にこだわらないのであれば、やれることが増えます。
ただし、これをするには、データサイエンティストにも三現主義(現場・現物・現実に向き合うこと)が必要です。 デスクワークで済む仕事ではなくなって来ます。
データサイエンティストではなく、日常的に三現の仕事をしている人が、データサイエンスのスキルを身に着けて実行するのも、ひとつの進め方です。
手段が目的になってしまうことへの対策です。
目的を中心にして、「DXやAIは様々な手段のひとつ」という位置付けにします。 つまり、DXやAIを使うことにこだわらないようにします。
会社では、日常的に、大小様々な問題が起きます。 また、長い目で見て、「こういう会社にしたい」という目標を持っていることもあります。 それらを中心にすると、「何をしたら良いのかがわからない」という状況は、劇的に変わります。
これを本当に実行するには、DXやAIの専門部署を作るにしても、教育をする部署に留める必要があります。 教育に留めずに、この部署に業務改革などを主導させると、手段を目的にした活動になります。
ちなみに、「手段が目的になってはいけない」と言う人は、筆者に限ったことではなく、ネットや本などでも見かけます。 しかし、そうは言っても、「DXやAIを使う」を必須の条件として残すことが、とても多いようです。 DXやAIを導入することが仕事になっている人は、「DX(AI)以外の手段でも良い」とはできないところが、この対策の難しいところです。
プロダクトアウトになってしまうことへの対策です。
例えば、異常が起きる問題については、原因について、当事者はわかっていたり、気付いていたりすることがあります。 それにも関わらず、異常がなくせないのは、何か理由があります。
その理由は、データや技術とは無関係で、人間関係や、特定の人の言動のこともあります。
マーケットインを目指すのなら、技術者の仕事では済まないこともありますが、やりがいは大きいです。
実際は、データがないことへの対策です。
データがないと、データサイエンティストは無力かというと、そうでもないです。
確率の知識や、分布の知識があると、わずかな事実から、データにはなっていないデータを想像できることがあります。 見えている事実から、因果関係や相関関係の仮説を立て、その仮説を検証するまでの道筋を自分で組み立てることもできます。
データがあるところからスタートした経験しかないと、雲をつかむような話に聞こえるかもしれませんが、慣れて来るとできるようになります。
大量にデータがあるけれども、それらは役に立たないことへの対策です。
社内にある大量のデータは、「眠っている」や、「使われていない」といった言われ方をすることがありますが、 実際は、何かに使われた後のデータです。
例えば、請求書や領収書のデータは、取引の時に使われています。社内に保管されているのは、保管の義務があるからです。
使われた後のデータを活用するのではなく、使う時のやり方を見直す方が、改善の余地が見つかりやすいです。
必要なデータがないのなら、自分で測るのが一番早く、確実なことがあります。
統計学は、もともと少ないデータから有意義な情報を得ようとして発展して来ています。 自分で測ると、量の少なさが気になるかもしれませんが、こんな時こそ、統計学の知識が役に立ちます。
順路
 次は
KPI
次は
KPI
