 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
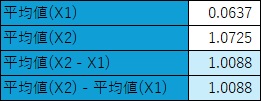
上の表は、サンプル数が100個のデータの集計結果です。
X1とX2という2つの変数があります。
X1とX2は独立しています。
この表から、X2とX1の差を計算してから、その平均値を計算した場合と、X1とX2について、個別に平均値を計算してから差を計算した場合で、同じになることがわかります。 つまり、個別処置効果が計算できなくても、平均処置効果は計算できます。
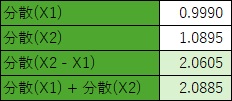
分散については、X2とX1の差を計算してから、その分散を計算した場合と、X1とX2について、個別に分散を計算してから和を計算した場合で、ほぼ同じになります。
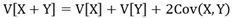
Vが分散で、Covが共分散です。
2つの変数が独立していると、理論上は、共分散は0になりますが、実際のデータでは、正確に0にはならず、ほぼ0になります。
そのため、「ほぼ同じ」という計算結果になります。
対応のないデータでは、個別のサンプルについて、「X2 - X1」が計算できません。
しかし、上記の平均値と分散の性質を使うと、「X2 - X1」が計算できないデータだとしても、「X2 - X1」という変数の、平均値と分散を近似的に求めることができます。
上記は、例えば、ランダム化比較試験のデータは、 「X2 - X1」が計算できないデータですが、そのデータでも、平均値(X2-X1)や、分散(X2-X1)の近似値が計算できる根拠です。
順路
 次は
仮想的な反事実の分析
次は
仮想的な反事実の分析
