If there is a set of data. We want to think that "I can do somehing great by Statistics and Machine Learning." But in many case, this thinking does not go well.
Outlier and Missing Value are one of the causes. But there are another one. Feature Engineering is needed.
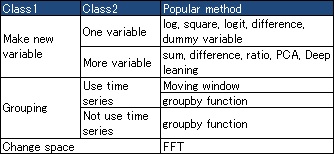
There are 3 kinds of approaches.
In my experience, using domain knowledge to make features is far more powerful than using statistical values (average etc.). I often use statistical values to find the hint to use domain knowledge.
Logarithmic, Square, Normalization, Logit Transformation and Probit Transformation, Dummy Variable, Differentiation Data and Integration Data, etc.
Addition Model and Division Model, Principal Component Analysis, Independent Component Analysis, Mahalanobis' Distance, Neural Network ( Deep Learning )
Often number of columns are decrease from that of raw-data. So this approach is important for edge-computing.
Average and Standard Deviation by groups are good. For example, grouping by months for maximum temperture data of every day. This approach is called, " Stratified Sampling" in Quality fields. This grouping is a major function of pibot tables in Excel and BI software.
Analysis of Type 2 in Sensor Data Analysis is an example using domain knowledege.
Mathematical space is changed. Fourier Transformation is famous.
NEXT  Probability and Random Variable Transformation
Probability and Random Variable Transformation
