Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
しきい値主成分分析 のRによる実施例です。 Rによる連関係数を使った主成分分析 と似ています。

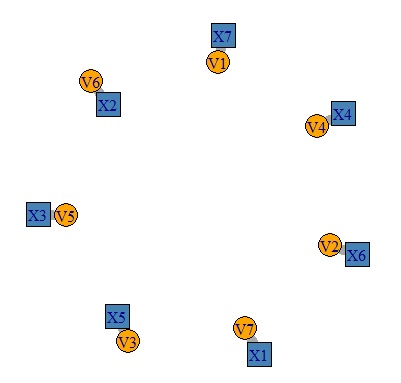
データは、上のようなものです。
7つの変数があり、まったく相関していません。
基本的に量的変数を扱う方法ですが、質的変数が入っている場合は、「#」を外せば、対応します。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
#library(fastDummies)
#Data <- dummy_cols(Data,remove_first_dummy = FALSE,remove_selected_columns = TRUE) # ダミー変換
GM2 <- cor(Data) # 相関係数行列

GM3 <- GM2
GM3[abs(GM3) < 0.1] <- 0 # 相関係数の絶対値の小さいものは0にする。

Eigen_analysis <- eigen(GM3) # 固有値分析
EA1 <- Eigen_analysis$values/sum(Eigen_analysis$values) # 全体への、各主成分の寄与率
EA1

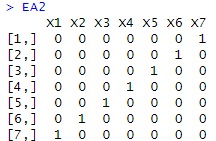
EA2 <- round(((sweep(Eigen_analysis$vectors, MARGIN=2, sqrt(Eigen_analysis$values), FUN="*")))^2,4) # 各変数への、各主成分の寄与率
rownames(EA2)<-colnames(Data) # 列名をつける
EA2
library(igraph)
pc4 <- EA2
pc4[pc4 < 0.1] <- 0
colnames(pc4)<- colnames(as.data.frame(pc4))
pc4<-pc4*10
DM.g<-graph_from_incidence_matrix(pc4,weighted=T)
V(DM.g)$color <- c("steel blue", "orange")[V(DM.g)$type+1]
V(DM.g)$shape <- c("square", "circle")[V(DM.g)$type+1]
plot(DM.g, edge.width=E(DM.g)$weight)