 R-EDA1偵傛傞僨乕僞暘愅 |
僂僃僽傾僾儕R-EDA1
R-EDA1偵傛傞僨乕僞暘愅 |
僂僃僽傾僾儕R-EDA1
R-EDA1偵傛傞僨乕僞暘愅 |
僂僃僽傾僾儕R-EDA1
R-EDA1偵傛傞僨乕僞暘愅 |
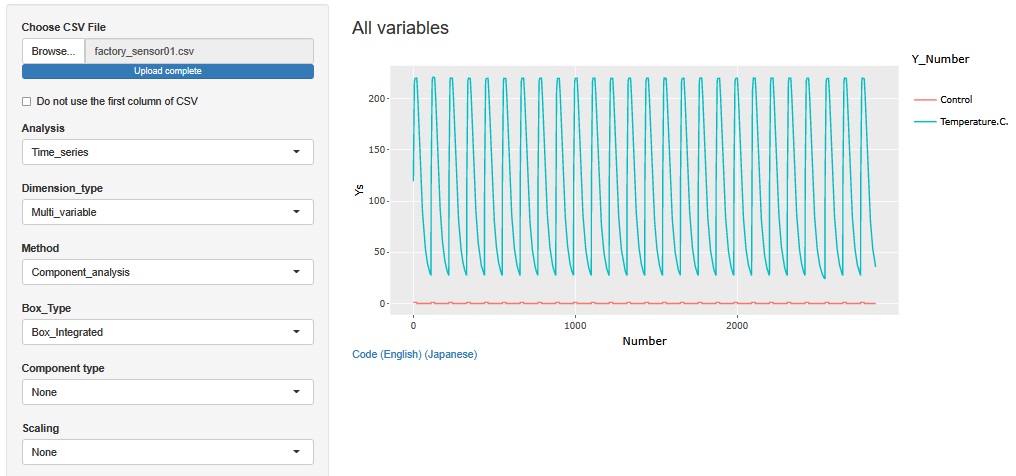
僂僃僽傾僾儕R-EDA1factory_sensor01偼丄岺応偱惢憿偟偰偄傞帪偺僨乕僞偱偡丅 昅幰偺抦傞尷傝偱偡偑丄偙偆偄偭偨僨乕僞偼丄 偦偺岺応偺旈枾偵側偭偰偄傞偙偲偑晛捠偱偡丅 偙偺儁乕僕偺僨乕僞偼丄昅幰偑揟宆揑側僷僞乕儞偵嬤偄宍偵側傞傛偆偵丄嶌偭偨傕偺偱偡丅
偙偺儁乕僕偱偼丄乽晄椙昳偺敪惗偺尨場偼壗偐丠乿丄乽晄嬶崌偺尨場偼壗偐丠乿偲偄偆尒曽偱丄 R-EDA1 偱暘愅傪偟偨帠椺偵側傝傑偡丅
R-EDA1偼枩擻偱偼側偄偺偱丄EXCEL傕暪梡偡傞曽恓偵偟偰偄傑偡丅
factory_sensor01.csv 偺儕儞僋愭偱丄偙偺僒僀僩撪偵曐懚偟偨csv僼傽僀儖傪僟僂儞儘乕僪偱偒傑偡丅 側偍丄曐懚偝傟偰偄傞僼傽僀儖偼丄乽factory_sensor01.csv乿側偺偱偡偑丄乽factory_sensor01.xls乿偲偄偆僼傽僀儖偲偟偰僟僂儞儘乕僪偝傟丄 乽奼挘巕偑偍偐偟偄乿偲偄偆堄枴偺僄儔乕儊僢僙乕僕偑弌傞応崌偑偁傝傑偡丅 偦偺応崌偼丄僟僂儞儘乕僪偝傟偨僼傽僀儖偺奼挘巕傪乽xls乿偐傜乽csv乿偵曄峏偡傟偽丄栤戣側偔巊偊傞傛偆偵側傝傑偡丅
偙偙偐傜偼丄擟堄偺応強偵偁傞乽factory_sensor01.csv乿偲偄偆僼傽僀儖傪巊偭偰偄傑偡丅
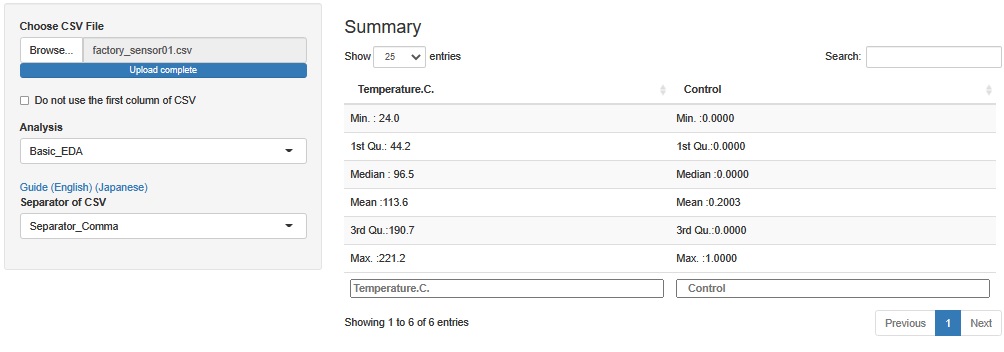
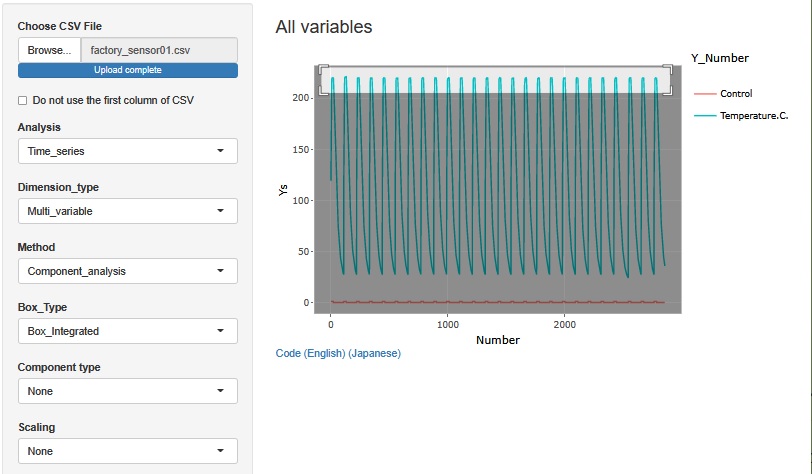
Temperature.C.乮壏搙[亷]乯偲丄Control乮惂屼乯偲偄偆丄俀偮偺曄悢偑偁傝傑偡丅 Temperature.C.偼丄嵟崅偑丄221.2亷丄嵟掅偑24.0亷偱偡丅 Control偼丄1偲0偺俀偮偺抣偑擖偭偰偄傑偡丅
嵟崅壏搙偼丄僷儞傗從壻巕傪從偔壏搙偲偩偄偨偄摨偠偱偡丅 嵟掅壏搙偼丄婥壏偔傜偄偵側偭偰偄傑偡丅
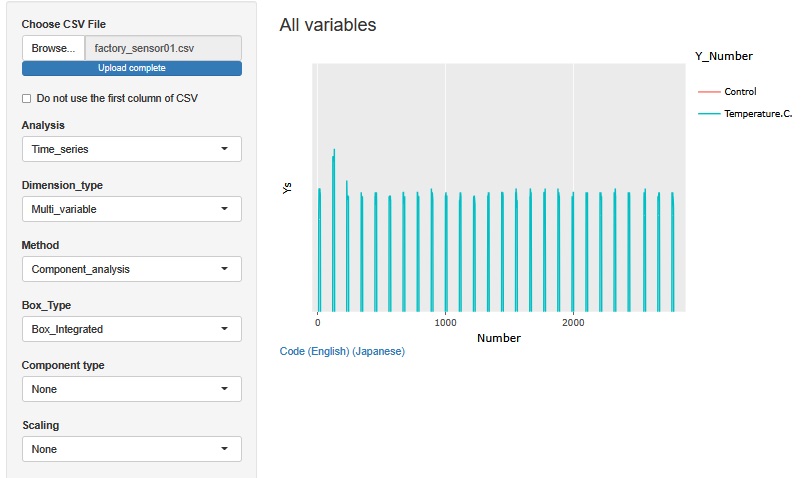
Temperature.C.偺嶳偑孞傝曉偟偰偄偰偄傑偡丅 偙偺傂偲偮偺嶳偑侾夞偺張棟傪昞偟偰偄傑偡丅 僶僢僠僾儘僙僗偲屇偽傟偰偄偰丄偙偺侾夞偑丄侾屄傗侾僙僢僩偺惢昳偺張棟偵側傝傑偡丅
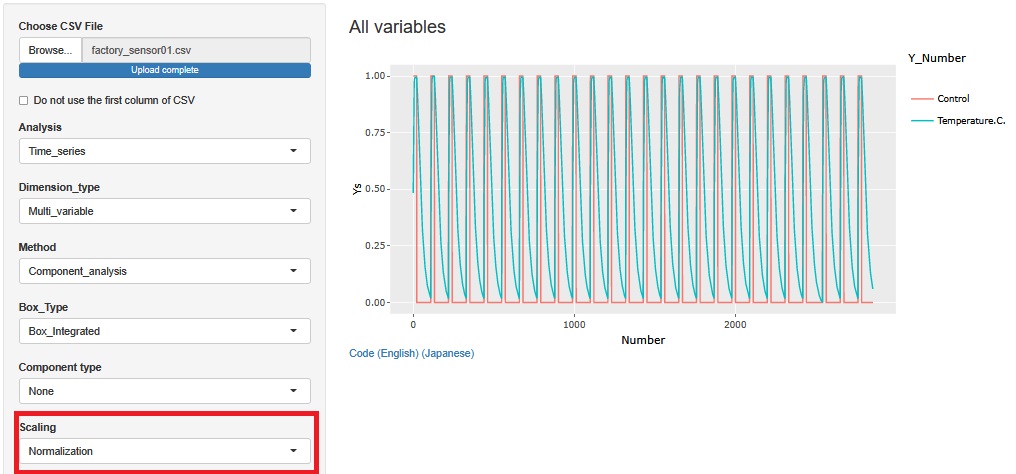
Normalization傪偡傞偲丄Control偺曄悢偺條巕傕傛偔傢偐傞傛偆偵側傝傑偡丅
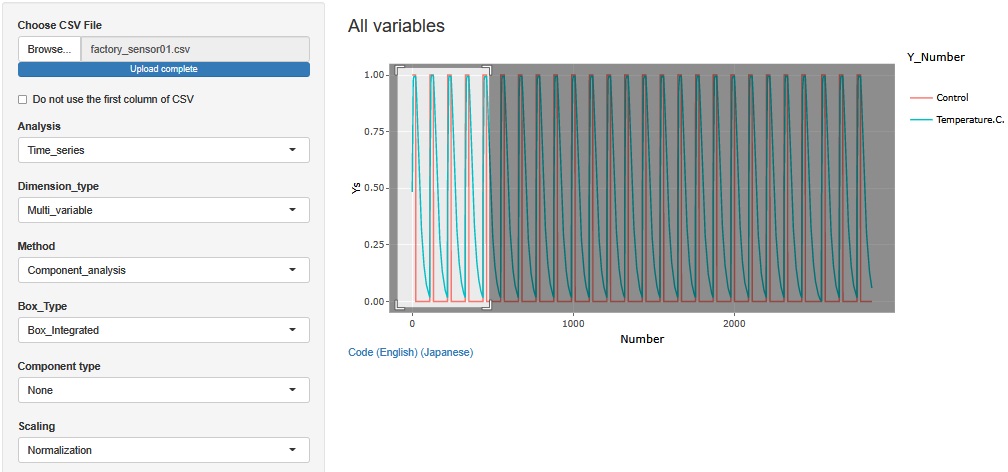
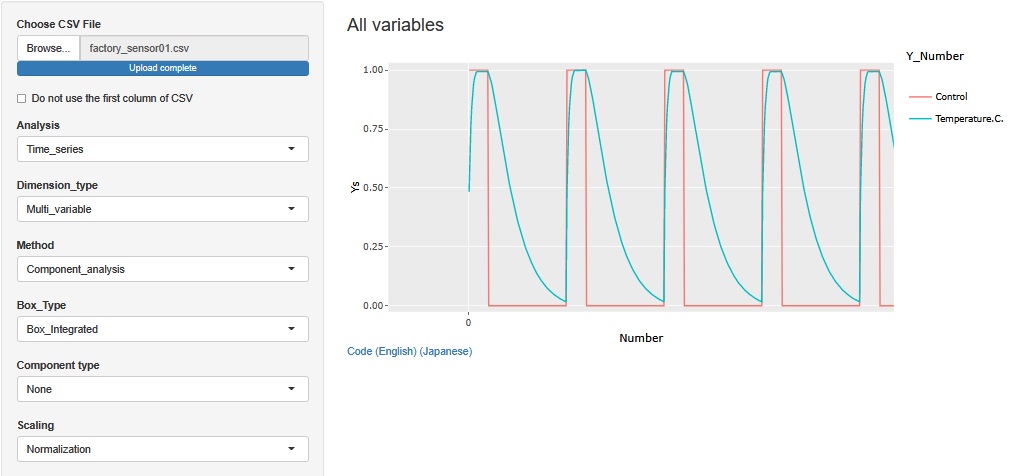
晹暘揑偵奼戝偡傞偲丄俀偮偺曄悢偺娭學偑傢偐傝傑偡丅 Control偑1偺娫偵丄Temperature.C.偼忋偑傝懕偗丄嵟戝抣偺偲偙傠傪偟偽傜偔堐帩偟偨屻偱丄0偵曄傢偭偨偲偙傠偱丄壓偑傝巒傔偰偄傑偡丅
攇宍偑孞傝曉偟偰偄傞偙偲偼忋婰偐傜傢偐傝傑偟偨偑丄偦傟埲忋偼傢偐傝偦偆傕側偄偱偡丅 偦偙偱丄孞傝曉偟侾夞暘偱廤寁偡傞宍偱丄 俀師僨乕僞乮摿挜検乯 傪嶌惉偟傑偡丅
壓恾偺愝掕偱偡偑丄傑偢丄暘愅懳徾偺曄悢偑Temperature.C.偱侾楍栚偵偁傞偺偱丄乽Temperature.C.乿偼乽侾乿偵偟偰偄傑偡丅 傑偨丄俀楍栚偺Control偑0偲1偵側偭偰孞傝曉偟偰偄傞偙偲傪棙梡偟偨偄偺偱丄乽Using_01variable_in_table乿傪乽Yes乿偵偟偰丄 乽Column of 01variable乿傪乽俀乿偵偟偰偄傑偡丅
愝掕偑偱偒傞偲廤寁寢壥偑弌傑偡丅 偙偺寢壥傪尒偰暘愅偡傞偙偲傕偱偒傑偡偑丄僌儔僼偱尒偰峴偒偨偄帪偼丄壓偵偁傞乽Dwonload type 2 data乿傪墴偟傑偡丅
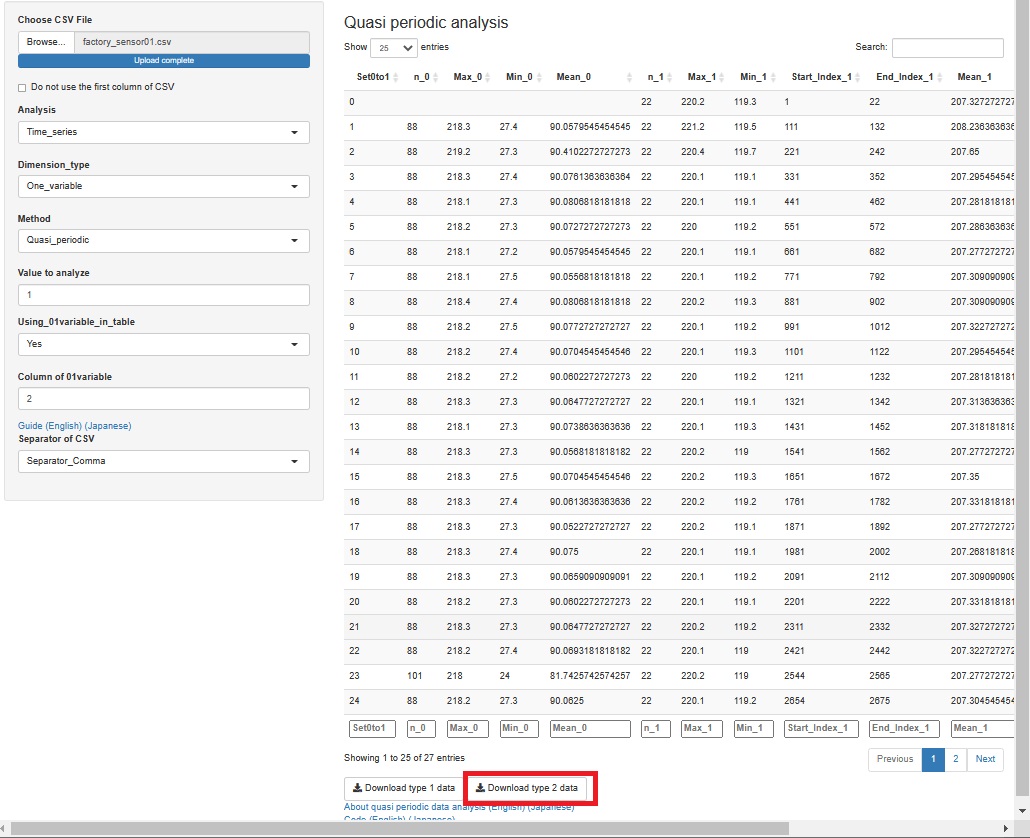
懡偔偺僨乕僞暘愅偱偼丄乽1乿偺娫偑惢憿偺昳幙傪嶌傞偨傔偵廳梫側偺偱丄乽0乿偺帪傪尒偰敪尒偑偁傞偙偲偼彮側偄偱偡丅 偟偐偟丄乽0乿偺帪偵婲偒偨偙偲偑丄乽1乿偺帪偵塭嬁偟偰偄偨傝丄崅壏偺帪偵尒偊側偄堎曄偑掅壏偺帪偵尒偊偨傝偡傞偙偲偑偁傞偺偱丄 乽0乿偺帪傕摿挜検偵偟偰偍偔偲椙偄偱偡丅
僶僢僠偺傑偲傔曽偲偟偰偼丄 乽11111丒丒丒100000丒丒丒0乿偱侾僶僢僠偲偟偰侾峴偵廤寁偡傞曽朄傕偁傝傑偡偑丄 偦偆偟偰偟傑偆偲丄乽0乿偺帪偺堎曄偑塭嬁偟偰偄傞偙偲偵婥晅偗側偔側傞偨傔丄 R-EDA1偱偼乽00000丒丒丒011111丒丒丒1乿偱丄侾僶僢僠偲偟偰侾峴偵廤寁偟偰偄傑偡丅
尦偺僨乕僞偼乽1乿偐傜巒傑偭偰偄傞偨傔丄嵟弶偺僶僢僠偼乽0乿偺帪偑側偄偙偲偵側傝傑偡丅 偦偺偨傔丄嵟弶偺僶僢僠偺n_0丄Max_0丄Min_0丄Mean_0偼寚懝抣偵側傝傑偡丅
巊偭偰偄傞婡婍偵傛傝傑偡偑丄昅幰偺応崌偼丄僟僂儞儘乕僪偟偨僼傽僀儖偼丄乽僟僂儞儘乕僪乿偲偄偆僼僅儖僟偵曐懚偝傟傑偡丅
墶幉傪侾楍栚偵偟偰丄俀楍栚埲崀偺慡曄悢偲偺娭學傪嶶晍恾偵偟傑偡丅 侾楍栚偼丄僶僢僠偺弴斣偵側傝傑偡偺偱丄僶僢僠枅偺廤寁僨乕僞偺帪宯楍暘愅偵側傝傑偡丅
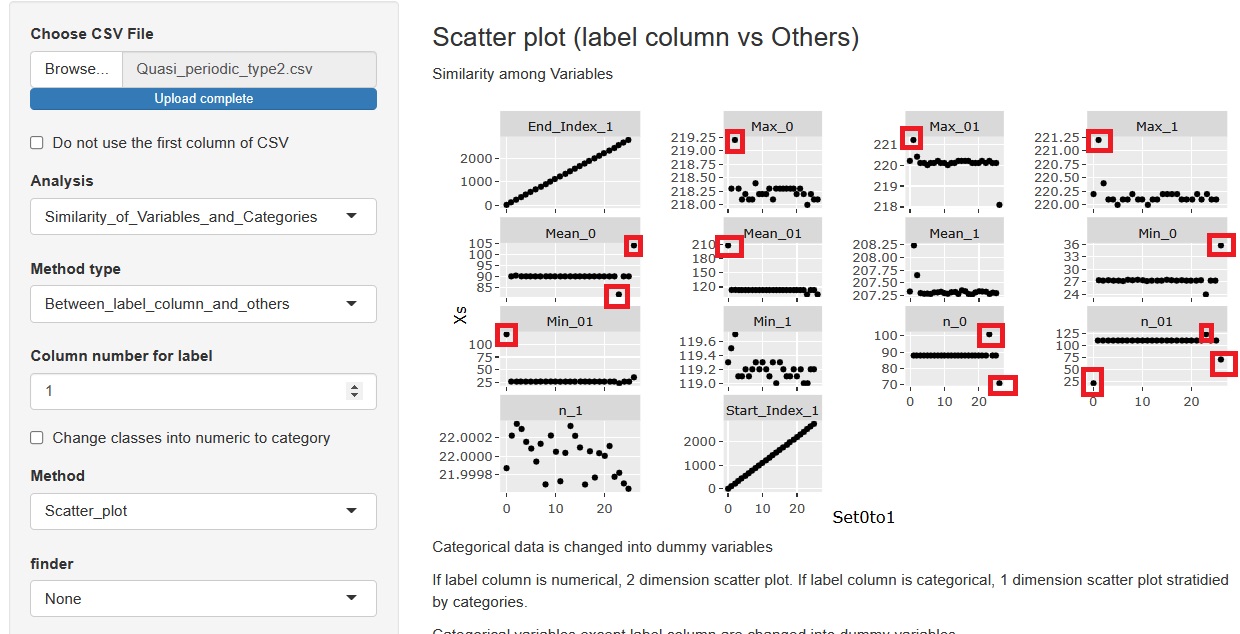
偲偙傠偳偙傠偱奜傟抣偑偁傞偙偲偑傢偐傝傑偡丅 偙偺屻偺暘愅偱偡偑丄椺偊偽丄乽晄椙昳偑敪惗乿丄乽堎暔偑敪惗乿偲偄偭偨尰徾偑侾偮偺僶僢僠偱婲偒偰偄傞偺偱偟偨傜丄 偦偺僶僢僠偺僞僀儈儞僌偑偳偙偵側傞偺偐傪挷傋傑偡丅 偦偺僶僢僠偺僞僀儈儞僌偱丄偳偙偐偱奜傟抣偑弌偰偄傞僞僀儈儞僌偑崌偆偺偱偟偨傜丄尰徾偲奜傟抣偵壗偐偺娭學偑偁傞偲峫偊傜傟傑偡丅 偦偆偡傞偲偦傟偑僸儞僩偵側偭偰丄婡夿偱壗偑婲偒偨偺偐丠丄婡夿偵壗傪偟偨偺偐丠丄偲偄偭偨峫嶡偑偱偒傞傛偆偵側偭偰棃傑偡丅
側偍丄嵟弶偲嵟屻偺僶僢僠偼丄侾僶僢僠暘偺僨乕僞偑晄懌偟偰偄傞偙偲偑偁傝丄奜傟抣偑弌傗偡偄偱偡丅 偦偺偨傔丄堎忢偺僞僀儈儞僌偑丄嵟弶傗嵟屻偺僶僢僠偵側傜側偄傛偆偵丄僨乕僞傪梡堄偡傞偺偑僐僣偵側傝傑偡丅
俀師僨乕僞偱嵟崅壏搙偵堘偄弌偰偄傑偡偺偱丄夵傔偰嵟弶偺僨乕僞傪僌儔僼偵偟偰傒傑偡丅
偦偟偰丄忋偺曽傪奼戝偟傑偡丅
偡傞偲丄妋偐偵俀僶僢僠栚偼嵟崅壏搙偑懠偺僶僢僠傛傝傕崅偄偙偲偑傢偐傝傑偡丅
俀師僨乕僞傪嶌傞偲丄尦偺僨乕僞偱偼婥晅偒偙偲偑擄偟偄偙偲偵娙扨偵婥晅偗傑偡丅 偦偆偟偰偐傜丄尦偺僨乕僞傪尒捈偡偲丄壗偑婲偙偭偰偄傞偺偐偺棟夝偑怺傑傝傑偡丅
factory_sensor01偼丄Temperature乮壏搙乯偺曄悢偺懠偵丄Control偲偄偆曄悢偑偁傝丄偙傟偑0偲1偵側偭偰偄偰丄僶僢僠偺孞傝曉偟偑傢偐傞偨傔丄僶僢僠枅偺廤寁偵巊偭偰偄傑偡丅
婡夿偵傛傞偺偱偡偑丄Control偺傛偆側曄悢偼丄暥帤捠傝Control乮惂屼乯偺忬懺傪昞偡曄悢偲偟偰丄婰榐偝傟偰偄傞偙偲偑偁傝傑偡丅
偙偺傛偆側曄悢偑側偔丄Temperature偩偗偺応崌偼丄Temperature偺孞傝曉偟偺巇曽傪棙梡偟傑偡丅
傑偢丄乽Using_01variable_in_table乮0-1偺曄悢傪巊偆乯乿傪乽No乿偵偟傑偡丅 傑偨丄乽Column to divide 0 or 1乮0偲1偵暘偗傞偨傔偺曄悢偺楍乯乿傪丄Temperature.C.偺楍偺乽1乿偵偟傑偡丅 偦偟偰丄乽Value to divide 0 or 1乿偵丄壏搙偱暘偗傞偨傔偺悢帤傪擖傟傑偡丅 椺偊偽丄乽50乿偵偟偨応崌偑丄壓恾偵側傝傑偡丅 乽50乿偵偡傞偲丄50傛傝崅偄娫偑乽1乿偵側傝丄掅偄娫偑乽0乿偵側傞曄悢傪怴偟偔嶌傝傑偡丅
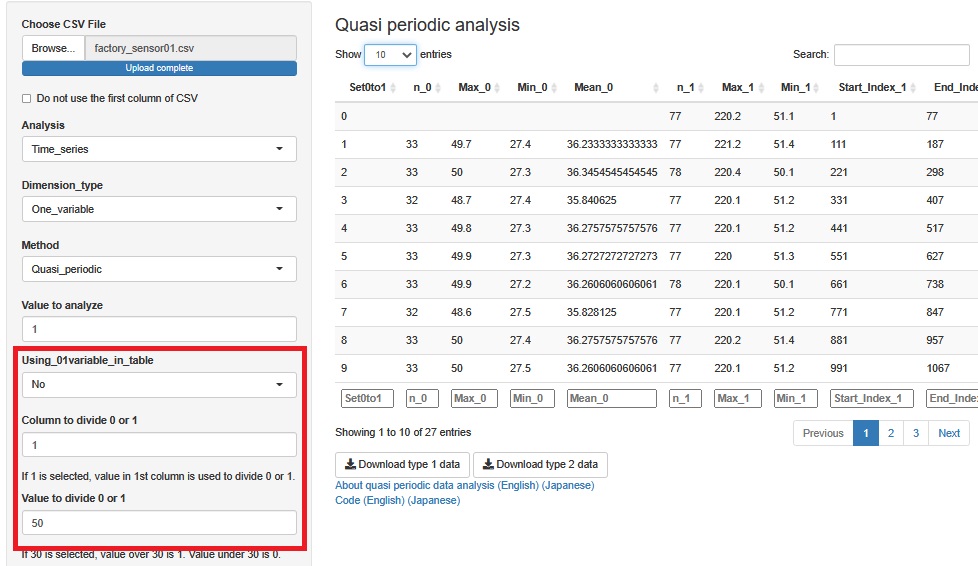
偙偺婡擻偼丄0-1偺曄悢偑側偄応崌偩偗偱側偔丄拲栚偟偨偄嬫娫傪偆傑偔愗傝弌偡曽朄偲偟偰巊偆偙偲傕偱偒傑偡丅
R-EDA1偱嶌傞偙偲偑偱偒傞俀師僨乕僞乮摿挜検乯偼丄慻傒崬傒娭悢偱娙扨偵嶌傞偙偲偑偱偒傞傕偺偱偡丅 偙傟偩偗偱傕栶偵棫偮応柺偼偨偔偝傫偁傝傑偡丅
偨偩丄傕偭偲暋嶨側尰徾偵側傞偲丄乽R-EDA1偱娙扨偵乿偲偄偆栿偵偼峴偐側偔側傝丄R丄Python丄VBA側偳傪巊偭偰僾儘僌儔儈儞僌傪偟偰丄桳岠側俀師僨乕僞傪嶌傞昁梫偑偁傝傑偡丅
幚嵺偺岺応偺僨乕僞偼丄傕偭偲暋嶨側攇宍傪偟偰偄偰丄偦偺攇宍偺宍偵惢憿忋偺堄枴偑偁傞偙偲傕偁傝傑偡丅 壏搙偵偄偔偮偐偺抜奒偑偁偭偨傝丄壏搙偺壓偘曽偑廳梫側偙偲傕偁傝傑偡丅
壏搙偵娭學偡傞曄悢偑偁傞応崌丄椺偊偽丄乽0偐傜1偵曄傢偭偨僞僀儈儞僌偺偦偺曄悢偺抣乿偲偄偆摿挜検偑桳岠側偙偲偑偁傝傑偡丅
factory_sensor01偼丄栺3000峴偺僨乕僞偱偡丅 偙傟偔傜偄偱傕丄俀師僨乕僞偺嶌惉偵悢昩偐偐傞偙偲偑偁傝傑偡丅乮張棟懍搙偺夵慞偼丄崱屻偺壽戣偲巚偭偰偄傑偡丅乯
幚嵺偺僙儞僒乕僨乕僞偼丄偙傟傛傝傕寘偑懡偄偙偲偑晛捠偱偡偑丄偄偒側傝慡晹傪帋偝側偄曽偑椙偄偱偡丅
乽栤戣偑婲偒偰偄傞帪偲丄婲偒偰偄側偄帪乿偺傛偆偵偟偰丄暘愅偡傞婜娫傪峣傝崬傫偩曽偑丄岠棪揑偱妋幚偵暘愅偱偒傑偡丅
戝偒側僨乕僞傪張棟偡傞応崌偺僐僣偲偟偰偼丄csv僼傽僀儖傪撉傒崬傫偩屻偱丄曄悢偺斣崋側偳傪巜掕偡傞弴斣偱偼側偔丄 巜掕偑廔傢偭偰偐傜丄嵟屻偵csv僼傽僀儖傪撉傒崬傫偩曽偑椙偄偱偡丅 偦偆偟側偄偲丄R-EDA1偼丄愝掕偺抣偑曄傢傞偛偲偵嵞寁嶼傪奐巒偡傞偨傔丄偨偩偱偝偊帪娫偺偐偐傞張棟偑師乆偲柦椷偝傟偰偟傑偄丄僼儕乕僘偟傑偡丅
