 R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
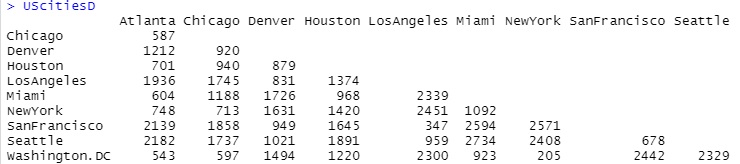
ウェブアプリR-EDA1UScitiesDとeurodistは、いずれも距離行列という特殊な行列になっています。 UScitiesDが米国の都市間で、eurodistがヨーロッパの都市間の距離のデータです。
このページでは、 R-EDA1 で分析をした事例になります。
筆者は、下記のコードでデータを入手して、csvファイルにしています。
Cドライブ直下のRtestというフォルダに保存します。
write.csv(as.data.frame(as.matrix(UScitiesD)), row.names = TRUE, "C:/Rtest/UScitiesD.csv")
write.csv(as.data.frame(as.matrix(eurodist)), row.names = TRUE, "C:/Rtest/eurodist.csv")
UScitiesD.csv と eurodist.csv のリンク先で、このサイト内に保存したcsvファイルをそれぞれダウンロードできます。 なお、保存されているファイルは、拡張子が「csv」なのですが、「xls」というファイルとしてダウンロードされ、 「拡張子がおかしい」という意味のエラーメッセージが出る現象があります。 ダウンロードされたファイルの拡張子を「xls」から「csv」に変更すれば、問題なく使えるようになります。
元のデータは、下三角行列なのですが、csvファイルでは、上三角に下三角の数字がコピーされたデータになっています。
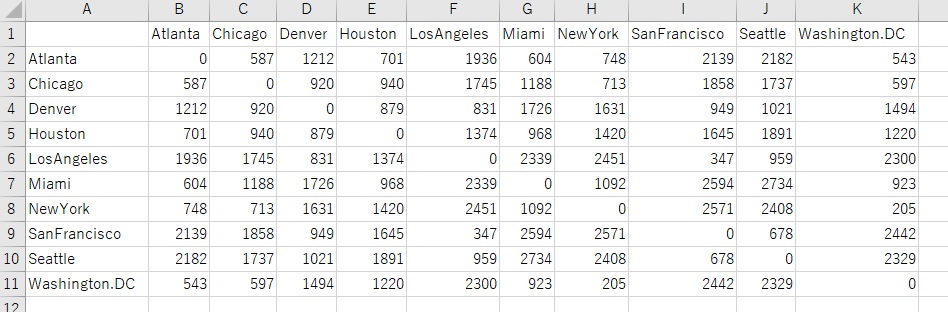
ここからは、任意の場所にある「UScitiesD.csv」と「eurodist.csv」いうファイルを使っています。
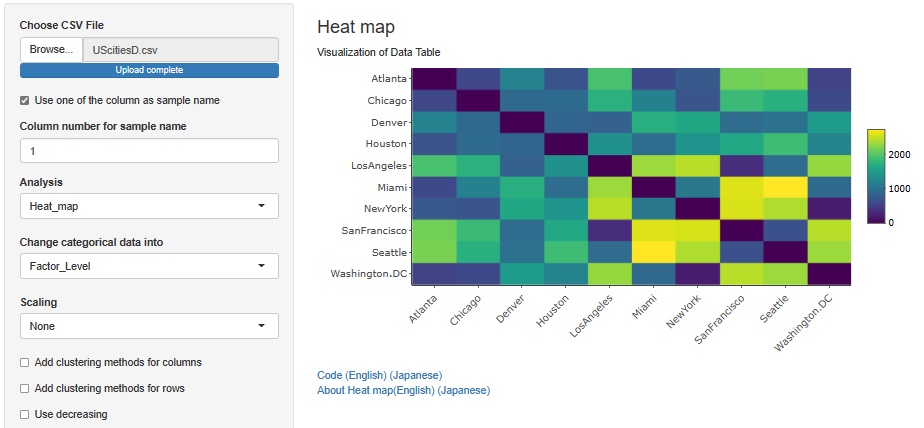
UScitiesDの距離行列の様子が色で分かります。
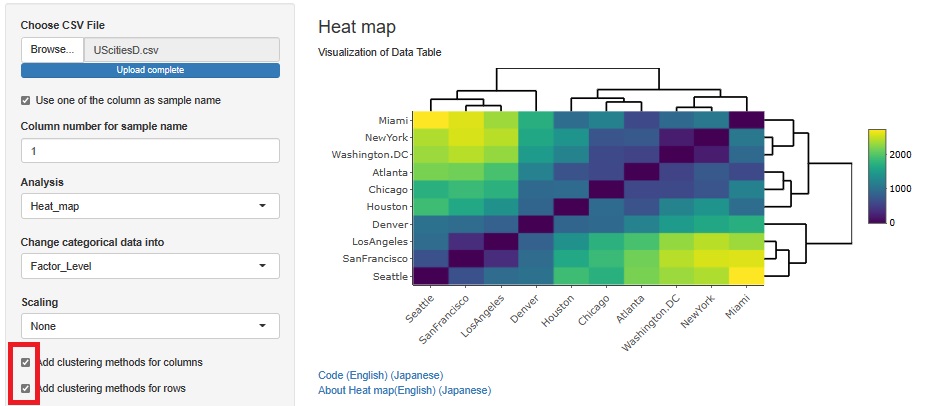
行と列の両方をクラスタリングすると、全体的な数字の様子がわかりやすくなりました。
UScitiesDでは、西側の都市が左側(と下側)に配置されて、東側の都市が右側(と上側)に配置されていて、隣同士は特に近い都市になっています。
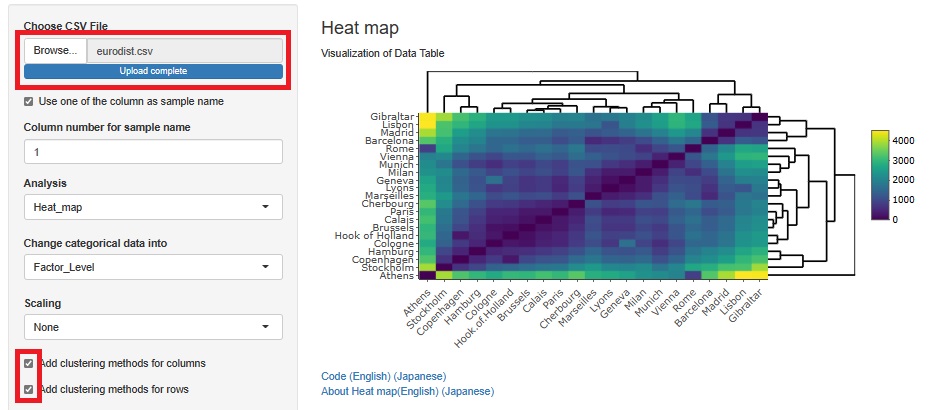
同じ方法をeurodistに使うと、北側の都市が下側(と左側)で、南側の都市が上側(と右側)での並び方になっていて、Atheneは例外的な扱いになっています。 Atheneは色合いがRomeと似ているのですが、このクラスタリングだと、AtheneとRomeは近くとして扱わませんでした。
多次元尺度構成法 で、距離行列から座標データを計算してみます。
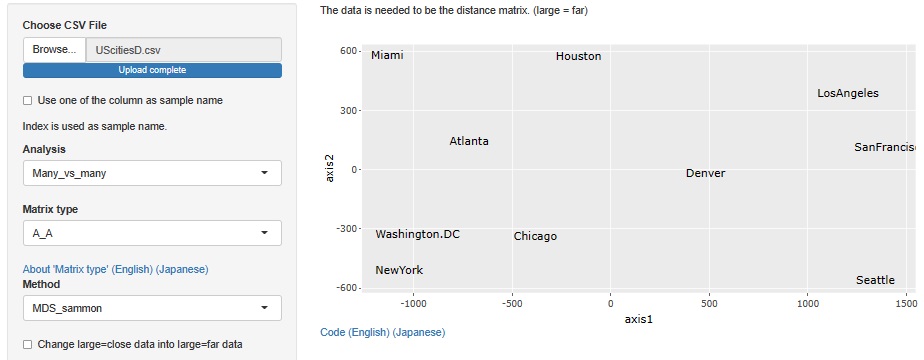
UScitiesDでは、東西が逆になった形で、本当の地図とほぼ同じような配置になりました。
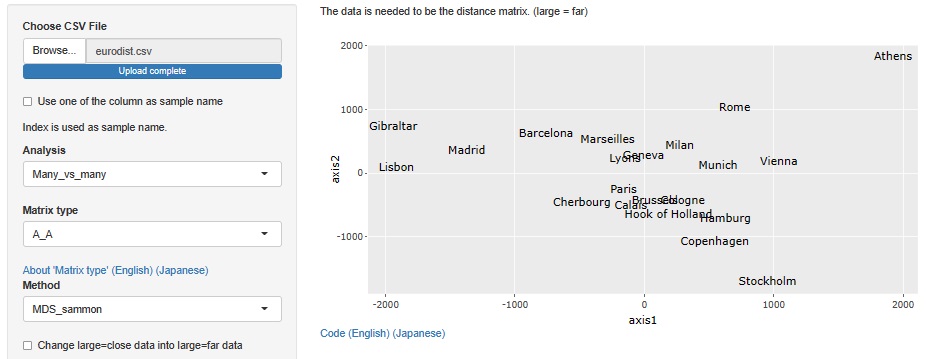
同じ方法をeurodistに使うと、南北が逆になった形の配置になりました。
