Python偵傛傞僨乕僞暘愅 |
R偵傛傞憡娭學悢暘愅
Python偵傛傞僨乕僞暘愅 |
R偵傛傞憡娭學悢暘愅
Python偵傛傞僨乕僞暘愅 |
R偵傛傞憡娭學悢暘愅
Python偵傛傞僨乕僞暘愅 |
R偵傛傞憡娭學悢暘愅
曄悢偺椶帡搙偺暘愅 偱偡丅
傕偲傕偲偺曽朄偼丄検揑曄悢偩偗偺僌儖乕僾偺庤朄偱偡偑丄 偙偺儁乕僕偺僐乕僪偼検揑丄幙揑偺椉曽偑巊偊傞傛偆偵偟偰偁傝傑偡丅
婎杮揑偵検揑曄悢傪埖偆曽朄偱偡偑丄幙揑曄悢偼 僟儈乕曄姺 偟偰幙揑丒検揑偑崿崌偟偰偄偨傝丄幙揑曄悢偩偗偱傕巊偊傞傛偆偵偟偰偁傝傑偡丅
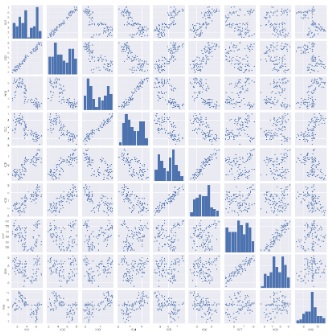
偙偺曽朄偺応崌丄幙揑曄悢摨巑偺暘愅寢壥偼丄 Python偵傛傞屄乆偺僇僥僑儕偺椶帡搙偺暘愅 偲帡偰棃傑偡丅
検揑曄悢偺椶帡搙傪尒傞曽朄偲偟偰嶶晍恾偼婎杮側偺偱丄 憤摉偨傝偺嶶晍恾傪尒傞偙偲偼戝帠偱偡丅
偨偩偟丄壓婰偼曄悢偑俋屄偺応崌偱偡偑丄偨偭偨俋屄偱傕偙偺屻偺暘愅偑恑傔偵偔偄僌儔僼偑偱偒偁偑傝傑偡丅 懠偺曽朄傪巊偭偰丄僌儔僼偵偡傞曄悢偼峣偭偨曽偑椙偄偱偡丅
import os #僷僢働乕僕偺撉傒崬傒
import pandas as pd #僷僢働乕僕偺撉傒崬傒
import matplotlib.pyplot as plt# 僷僢働乕僕偺撉傒崬傒
import seaborn as sns # 僷僢働乕僕偺撉傒崬傒
from sklearn import preprocessing # 僷僢働乕僕偺撉傒崬傒
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # Pandas偺Plot偺僌儔僼偺尒偨栚傪seaborn晽偵偡傞丅僌儔僼偺僼僅儞僩傪愝掕偡傞
os.chdir("C:\\PyTest") # 嶌嬈梡僨傿儗僋僩儕傪曄峏
df= pd.read_csv("Data.csv" , engine='python')# 僨乕僞傪撉傒崬傒
df2 = pd.get_dummies(df)# 幙揑曄悢偼僟儈乕曄姺
sns.pairplot(df2) # 憤摉偨傝偺嶶晍恾傪嶌傞
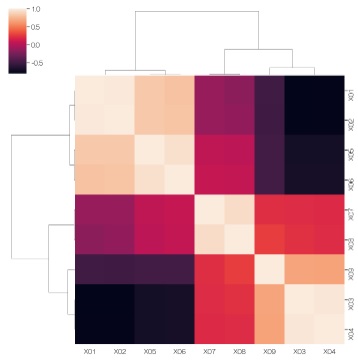
憡娭學悢傪寁嶼偟偰丄僋儔僗僞儕儞僌晅偒偺僸乕僩儅僢僾偱僌儔僼偵偡傞曽朄偱偡丅
import os #僷僢働乕僕偺撉傒崬傒
import pandas as pd #僷僢働乕僕偺撉傒崬傒
import matplotlib.pyplot as plt# 僷僢働乕僕偺撉傒崬傒
import seaborn as sns # 僷僢働乕僕偺撉傒崬傒
from sklearn import preprocessing # 僷僢働乕僕偺撉傒崬傒
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # Pandas偺Plot偺僌儔僼偺尒偨栚傪seaborn晽偵偡傞丅僌儔僼偺僼僅儞僩傪愝掕偡傞
os.chdir("C:\\PyTest") # 嶌嬈梡僨傿儗僋僩儕傪曄峏
df= pd.read_csv("Data.csv" , engine='python')# 僨乕僞傪撉傒崬傒
df2 = pd.get_dummies(df)# 幙揑曄悢偼僟儈乕曄姺
df3 = df2.corr() # 憡娭學悢峴楍傪寁嶼
sns.clustermap(df3, method='ward', metric='euclidean') # 僋儔僗僞儕儞僌晅偒偺僸乕僩儅僢僾