 僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
乽惓忢丒堎忢乿丄乽慞丒埆乿丄乽崌奿丒晄崌奿乿丄乽岠壥偁傝丒側偟乿丄乽岲挷丒晄挷乿丄乽懡悢攈丒彮悢攈乿側偳丄嫇偘傟偽僉儕偑側偄偔傜偄丄 擔忢偱偼丄擇抣傪巊偭偰暔帠傪棟夝偟偰偄傑偡丅
擇抣偵偡傞偲丄尵梩偱昞尰偱偒偨傝丄曽岦惈傪柧妋偵偱偒偰曋棙偱偡丅
偨偩丄僨乕僞暘愅傪偡傞帪偼丄擇抣偵側偭偰偄傞榖傪擇抣偺傑傑巊偆偺偱偼側偔丄楢懕僨乕僞偵偟偨曽偑怺偔暘愅偱偒傞偙偲偑偁傝傑偡丅
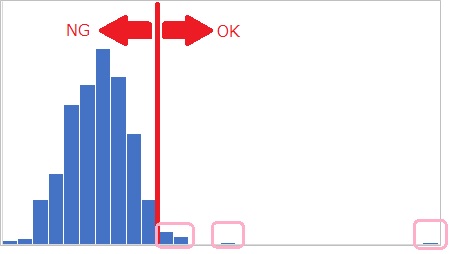
乽楢懕僨乕僞巚峫乿偲偄偆偺偼丄昅幰偺憿岅偱偡丅
椺偊偽丄忋恾偺傛偆偵乽OK丒NG乿偺攚宨偵偁傞楢懕僨乕僞傪暘愅懳徾偵偡傞偺偑丄楢懕僨乕僞巚峫偱偡丅
乽OK丒NG乿偺傑傑偩偲丄 儔儀儖暘椶 偑僨乕僞暘愅偺曽朄偵側傝傑偡偑丄 楢懕僨乕僞偩偲丄 夞婣暘愅 偑巊偊傞傛偆偵側傝傑偡丅
楢懕僨乕僞偵偡傞偲丄埖偊傞忣曬偑憹偊傑偡丅 椺偊偽丄忋恾偩偲丄NG偲偄偆揰偱偼摨偠偱傕丄OK偺斖埻偵嬤偄NG偲丄墦偄NG偱偼丄尨場偑堘偆壜擻惈偑偁傝傑偡偑丄 偦偆偟偨偙偲傪挷傋傜傟傞傛偆偵側傝傑偡丅
摑寁揑場壥悇榑 偱偼丄乽岠壥偁傝丒側偟乿偺擇抣偱偼側偔丄 場壥岠壥 偲偄偆楢懕僨乕僞偱岠壥傪暘愅偡傞曽朄偑偁傝傑偡丅
忋偺椺偺傛偆偵丄尵梩偱偼乽OK乿偲乽NG乿偲偟偰丄偼偭偒傝偲暘偐傟偰偄偰傕丄 OK偵嬤偄NG偺僒儞僾儖偲丄NG偵嬤偄OK偺僒儞僾儖偼丄慡懱揑側堘偄偐傜峫偊傞偲丄乽摨偠乿偲尵偊傞傛偆側偙偲偑偁傝傑偡丅
OK偲NG偱偼側偔丄楢懕僨乕僞偺曽偵懳偟偰丄尨場暘愅傪恑傔偨曽偑丄暘愅偺尒捠偟偑椙偔側傝傑偡丅
寛掕栘 偵偼丄栚揑曄悢偑幙揑偐検揑偐偺堘偄偱丄 暘椶栘偲夞婣栘 偵暘偐傟傑偡丅
擇抣偺応崌偑暘椶栘側偺偱丄楢懕僨乕僞巚峫偺帪偼丄夞婣栘偵偡傟偽椙偄偺偐偲偄偆偲丄偦偆偱傕側偄偱偡丅 夞婣栘偼検偺埖偄曽偑慹偄偨傔丄偁傑傝椙偔側偄偱偡丅
儌僨儖栘 偼夞婣栘偺堦庬偱偡偑丄堦斒揑側夞婣栘傛傝傕検偺曄壔傪埖偊傞傛偆偵側偭偰偄偰曋棙偱偡丅
弴楬
 師偼
恖岺抦擻乮AI乯
師偼
恖岺抦擻乮AI乯
