 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
クラスター分析 では、サンプルがどのように分けられるのかを見て、近いもの同士をクラスターにします。
どのクラスターに属するのかがわからない新しいサンプルがあった時に、そのサンプルとクラスターの関係を調べるのが、このページの方法です。
クラスター分析で予測をする時には、「どのクラスターに属しているのか?」という作業を、予測の前の作業として実施します。
例えば、左のようなデータについて、クラスター分析をすると、右のように3つのクラスターを抽出できます。
予測の時は、この結果を使います。
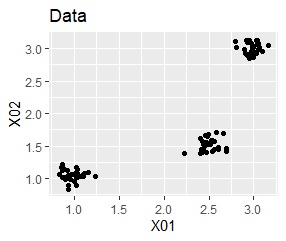
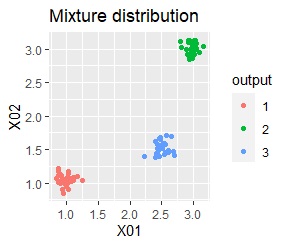
混合分布法はクラスター分析の一種ですが、クラスター分けだけではなく、 クラスター分けをする時に使ったサンプル以外のサンプルについて、「どのクラスターに属しているのか?」という 統計モデルによる予測 ができる方法です。
例えば、上記の作業の結果を使って、任意の位置のクラスターを予測すると、下図になります。
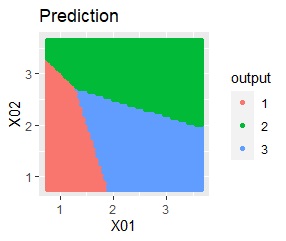
混合分布法は、それ自体が予測に使えるようになっています。 混合分布法以外のクラスター分析の手法も、クラスターの予測には使えます。
クラスター分析でクラスターの名前のある変数を作ってから、その変数をラベルにして、 ラベル分類 の手法を使う手順になります。
クラスター分析の手法と、ラベル分類の手法の組合せで、いろいろなバリエーションができます。
Rによる混合分布法によるクラスターの予測の方法は、 Rによるクラスターの予測 のページにあります。
順路
 次は
クラスター外の予測の分析
次は
クラスター外の予測の分析
