There are many different ways to say "data."
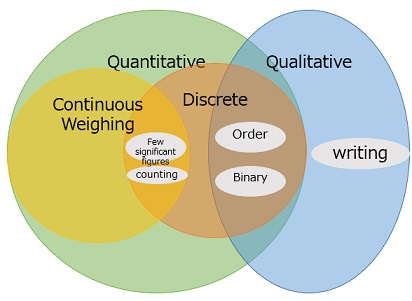
First of all, there is a difference that you can see at a glance. Quantitative and qualitative, continuous and discrete, etc. In addition, there are differences in the nature of the data.
Quantitative data is data expressed as numerical values such as "1, 2, 3".
Qualitative data is data represented by letters such as "A, B, C" and other characters. Even if it is expressed numerically, if the size of the numerical value is meaningless, such as address 1 or 2, it is treated as qualitative data.
One way to use data science is to distinguish between qualitative data and quantitative data, but to put all quantitative data in the same model. For example, you might want to apply multiple regression analysis to a dataset that does not know the meaning of the data in detail. However, with that approach, when it doesn't work, the only direction is to use a nonlinear complex model.
Distinguishing between quantitative data can be helpful when proceeding with mathematical modeling approaches.
Both continuous and discrete data are quantitative.
Continuous data, like temperature, is, in principle, data with almost infinitely fine values.
Discrete data is data that has only jumping numbers. Data that seems to have only integer values is typical.
Note that if there are few Significant Figures, even if it is continuous data, it will look discrete. For example, whether to think of one-step data as continuous data or discrete data depends on the case.
Counting data is quantitative data.
Weighing data means almost the same as continuous data.
Counting data, such as number of people and frequency, is data that only exists as an integer greater than or equal to 0. In this case, it's a type of discrete data.
In this way, "ratio" can be calculated by dividing the counting data by the counting data, but the ratio is the counting data. Ratio mathematics uses the mathematics of counting data. If you only look at the data as discrete or continuous, it is difficult to judge whether it is counted data or not.
Even in quantitative data, length, weight, energy, ratio, etc. represent size.
Location data represents not only position in the everyday sense, such as coordinates, but also temperature.
Incidentally, for example, as there is a relationship between energy and temperature, magnitude data and position data are not completely separate.
Scalars and vectors are common views of data in physics.
The scalar is the same as the magnitude data above. A vector is something that has a size and orientation, for example, speed or force.
Additive data is data that can be added, and non-additive data is data that cannot be added.
Among the size data, length and weight are additive. Ratio data can be both additive and non-additive, and depends on the contents of the numerator and denominator.
Location data is non-additive.
Additive data is being studied mathematically in Measure Theory.
Qualitative data is handled in a rudimentary way of aggregating such as "counting the number of occurrences". Applications can be expanded by treating it like quantitative data (discrete data).
For example, if you run a marathon, You can have sequential data such as 1, 2, 3, 4, etc., but the time between the sequences is different. Sequential data has these characteristics:
Ordinal data is classified as qualitative data in textbooks. Given that sequence intervals are meaningless, they can also be treated as quantitative data.
Binary data is a type of qualitative data. It is data with only two values, such as "with / without", "true / false", "OK / NG", "good / defective product", "front / back", etc. Binary data is logically easy to handle, so it is easy to process various things in programming. Also, if you convert each to "0" and "1", you will be able to treat them as numbers. There are various methods such as Quantification theory and a href="ede1-9-3-5-2.html">time series analysis of 0-1 data.
In pattern recognition, it is sometimes used to convert between "-1" and "1" and "determine which one is greater than 0".
NEXT  Errors
Errors
