 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
カテゴリの類似度の分析 の方法です。
基本的には質的変数に対しての方法ですが、量的変数は、 1次元クラスタリング の方法で、質的変数に変換するコードが入っているので、 質的・量的が混合していたり、量的変数だけでも使えるようにしてあります。
量的変数だけの場合は、変数の非線形の関係を分析する方法として使えます。
個々のカテゴリの相関分析 の実施例は下記になります。 (下記は、コピーペーストで、そのまま使えます。 この例では、Cドライブの「Rtest」というフォルダに、 「Data.csv」という名前でデータが入っている事を想定しています。 このコードの前に、ライブラリ「dummies」と「reshape」と「ggplot2」のインストールが必要です。
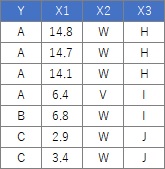
下の表は一部で、実際は106行分あります。
データは、質的データと量的データが混ざったものです。
量的データは、
1次元クラスタリング
で質的データに変換して分析することにしています。
こうすると、
決定木
と併用しやすくなります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
library(dummies) # ライブラリを読み込み
Data <- read.csv("Data.csv", header=T) # データを読み込み
for (i in 1:ncol(Data)) { # ループの始まり。データの列数を数えて同じ回数繰り返す
if (class(Data[,i]) == "numeric") { # 条件分岐の始まり
Data[,i] <- droplevels(cut(Data[,i], breaks = 5,include.lowest = TRUE))# 5分割する場合。量的データは、質的データに変換する。
} # if文の処理の終わり
} # ループの終わり
Data_dmy <- dummy.data.frame(Data)# ダミー変換
corr <- cor(Data_dmy)# 相関行列を作る
#ここまでが分析用のデータの作成。この後は、いろいろなグラフの作成。まず相関行列のヒートマップから。
library(reshape)# ライブラリを読み込み
library(ggplot2)# ライブラリを読み込み
corr2 <-corr# 相関行列を作る
corr3 <- melt(corr2)# グラフ用のデータに変換
ggplot(corr3, aes(X1, X2, fill = value)) + geom_tile() + scale_fill_gradient(low = "white", high = "blue")# グラフにする
#棒グラフ
corr2[upper.tri(corr2,diag=TRUE)] <- 0 # 出力用のデータに変換
corr4 <- melt(corr2)# 出力用のデータに変換
corr4$set <- paste(corr4$X1,"_",corr4$X2)# 出力用のデータに行を追加
corr4 <- corr4[order(corr4$value, decreasing=T),]# 出力用のデータをソート
ggplot(head(corr4,10), aes(x=value, y=reorder(set, value))) + geom_bar(stat = "identity") # 上位10セットの棒グラフを描く
#ネットワークグラフ
library(igraph) #ライブラリを読み込み
corr5 <-corr# 相関行列を作る
diag(corr5) <- 0 # 対角成分は0にする
corr5[corr5<0.1] <- 0 # 相関係数が0.1未満の場合は0にする(非表示にするため)
corr5 <- corr5*10 # 一番大きな値が10になるように修正(パスの太さを指定するため)
corr6 <- graph.adjacency(corr5,weighted=T, mode = "undirected") # グラフ用のデータを作成
plot(corr6, edge.width=E(corr6)$weight) # グラフを作成

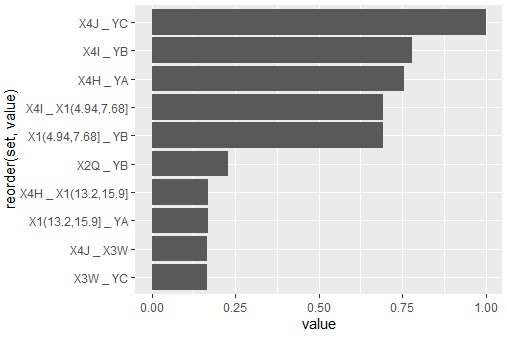
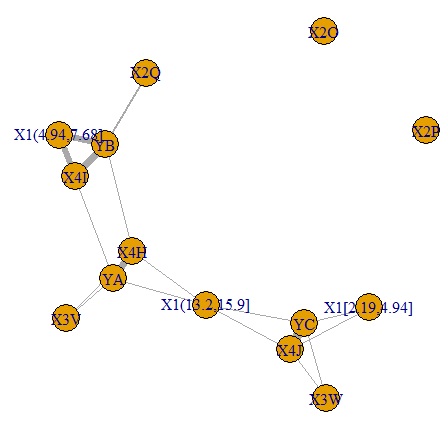
YA、YB、YCが、それぞれ密接な関係を持つカテゴリを持っていることと、YBについては、3つのカテゴリでグループを作っていることがわかりました。
