 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
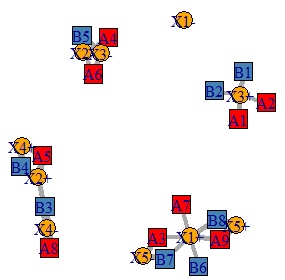
3部グラフ の例です。
3部グラフ を作る方法です。
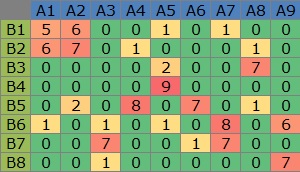
この例では、Cドライブの「Rtest」というフォルダに、
「Data.csv」という名前で分割表になっているデータが入っている事を想定しています。
library(MASS) # パッケージを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T, row.names=1) # データを読み込み
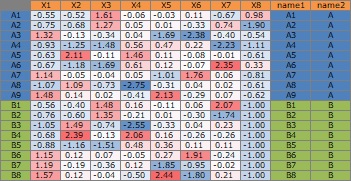
pc <- corresp(Data,nf=min(ncol(Data),nrow(Data))) # コレスポンデンス分析
pc1 <- pc$cscore # スコアを読み取り
pc1 <- transform(pc1 ,name1 = rownames(pc1), name2 = "A")# 行名を追加
pc2 <- pc$rscore # スコアを読み取り
pc2 <- transform(pc2 ,name1 = rownames(pc2), name2 = "B")# 列名を追加
Data1 <- rbind(pc1,pc2)# データを結合
round(pc$cor^2/sum(pc$cor^2),2)# 寄与率を求める。

# 「Data1」というデータは、下のようになっています。これをこの後のグラフ作成に使います。
MaxN = 5# 使用する固有値の数を指定
library(igraph) # パッケージを読み込み
library(sigmoid) # パッケージを読み込み
Data1p = Data1[,1:MaxN]# 分析対象のデータを抽出
names(Data1p) = paste(names(Data1p),"+",sep="")# 列名を変更
DM.matp = apply(Data1p,c(1,2),relu)# 0以下の値は0に変換
Data1m = -Data1[,1:MaxN]# 分析対象のデータを抽出。符号を反転
names(Data1m) = paste(names(Data1m),"-",sep="")# 列名を変更
DM.matm = apply(Data1m,c(1,2),relu)# 0以下の値は0に変換
DM.mat =cbind(DM.matp,DM.matm)# プラス側とマイナス側を合体
DM.mat <- DM.mat / max(DM.mat) * 10 # 値が0から10になるように変換
DM.mat[DM.mat < 4] <- 0 # 絶対値が4未満の場合は0にする(非表示にする)
DM.g<-graph_from_incidence_matrix(DM.mat,weighted=T) # グラフ用のデータを作る
V(DM.g)$color <- c("steel blue", "orange")[V(DM.g)$type+1] # 色を変える
V(DM.g)$color[1:ncol(Data)] <- "red" # 色を変える。ncol(Data)はAの要素の数
V(DM.g)$shape <- c("square", "circle")[V(DM.g)$type+1] # マークの形を変える
plot(DM.g, edge.width=E(DM.g)$weight) # グラフを作る
表の値は、質的データの場合です。

行の項目名が1列目、列の項目が2列目、値が3列目になるようにデータを並べ変えてから使います。
library(tidyr) # ライブラリの読み込み
library(dplyr) # ライブラリの読み込み
library(igraph) # ライブラリの読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data1 <- tidyr::gather(Data, key="Name2", value = Val, -Name) # 縦型に変換(Nameの列以外を積み上げる)
Data21 <- Data1# 縦型に変換(Nameの列以外を積み上げる)
Data21[,2] <- NULL # # データから2列目を消す
Data22 <- Data1[,2:3] # # 1列目のないデータを作る
names(Data22)[1] <- "Name"# 列名を変更
Data31 <- count(group_by(Data21,Data21[,1:2],.drop=FALSE)) # # 重複している組み合わせを集計
Data32 <- count(group_by(Data22,Data22[,1:2],.drop=FALSE)) # # 重複している組み合わせを集計
Data4 <- rbind(Data31,Data32)# データを縦に結合
Data5 <- Data4
Data5$n <- Data4$n/max(Data4$n)*5 # 辺の太さを調整
DM.g<- graph.data.frame(Data5[,c(1,2)], directed = F) # グラフ用のデータを作る
E(DM.g)$weight <-Data5[[3]]# 辺のデータを取る
plot(DM.g, edge.width=E(DM.g)$weight) # グラフを作る
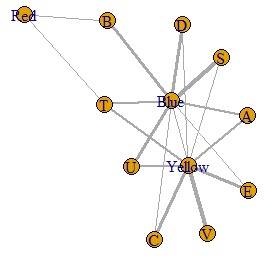
この結果は、解釈しにくいですが、とりあえずデータがグラフになりました。
