Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
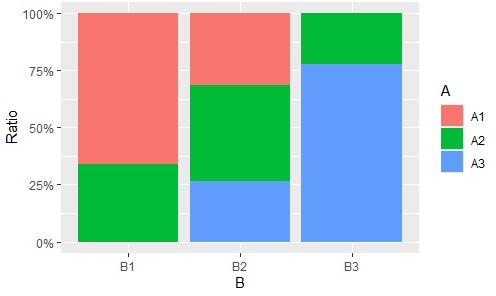
効果量として 連関係数 、P値の計算に独立性の検定を計算し、グラフとして100%積み上げ縦棒を作ります。
変数の類似度の分析 です。
基本的に質的変数を扱う方法ですが、量的変数は 1次元クラスタリング の方法で、質的変数に変換するコードが入っているので、 質的・量的が混合していたり、量的変数だけでも使えるようにしてあります。
library(vcd) #ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data1 <- Data # 1次元クラスタリングの出力先を作る
n <- ncol(Data1) # データの列数を数える
for (i in 1:n) {
if (class(Data1[,i]) == "numeric") {
Data1[,i] <- droplevels(cut(Data1[,i], breaks = 3,include.lowest = TRUE))# 3分割する場合。量的データは、質的データに変換する。
} # if文の処理の終わり
} # ループの終わり
cross<-xtabs(~Data1[,1]+Data1[,2],data=Data1)# 1列目と2列目の変数の分割表を作成
res<-assocstats(cross)# 連関分析
cramer_v<-res$cramer# クラメールの連関係数の抽出
cramer_v
chisq.test(cross)# カイ二乗検定(独立性の検定)
library(ggplot2)
ggplot(Data1, aes(x = Data1[,2], fill = Data1[,1])) +
geom_bar(position = "fill") +
scale_y_continuous(labels = scales::percent) +
labs(x = colnames(Data1)[2], y = "Ratio", fill = colnames(Data1)[1])