 R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1airqualityは、空気の測定データです。 欠損値がある点、時系列データになっている点、量的変数だけの多変量データになっている点が特徴です。
このページでは、「このデータはどうなっているのか?」、「このデータから、どんなことがわかるのか?」という見方で、 R-EDA1 で分析をした事例になります。
R-EDA1は万能ではないので、EXCELも併用する方針にしています。
筆者は、下記のコードでデータを入手して、csvファイルにしています。
Cドライブ直下のRtestというフォルダに保存します。
write.csv(airquality, row.names = FALSE, "C:/Rtest/airquality.csv")
airquality.csv のリンク先で、このサイト内に保存したcsvファイルをダウンロードできます。 なお、保存されているファイルは、「airquality.csv」なのですが、「airquality.xls」というファイルとしてダウンロードされ、 「拡張子がおかしい」という意味のエラーメッセージが出る現象があります。 ダウンロードされたファイルの拡張子を「xls」から「csv」に変更すれば、問題なく使えるようになります。
ここからは、任意の場所にある「airquality.csv」というファイルを使っています。
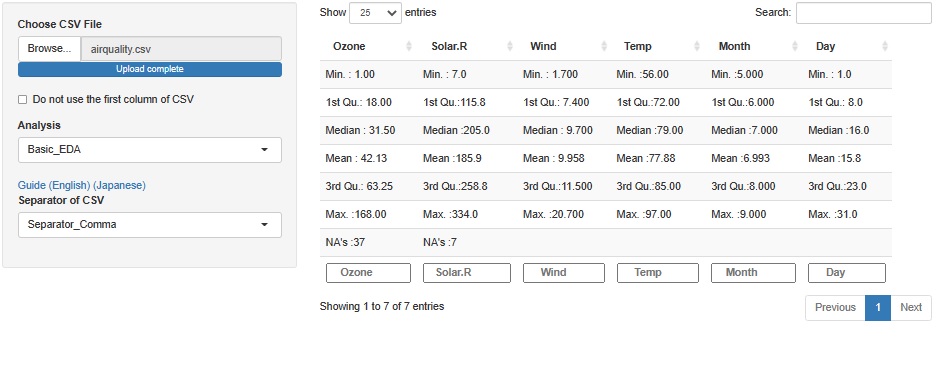
Ozoneが「NA's :37」、Solar.Rが「NA's :7」となっていて、欠損値が入っています。
時刻の情報が、MonthとDayという変数にして、入れられています。
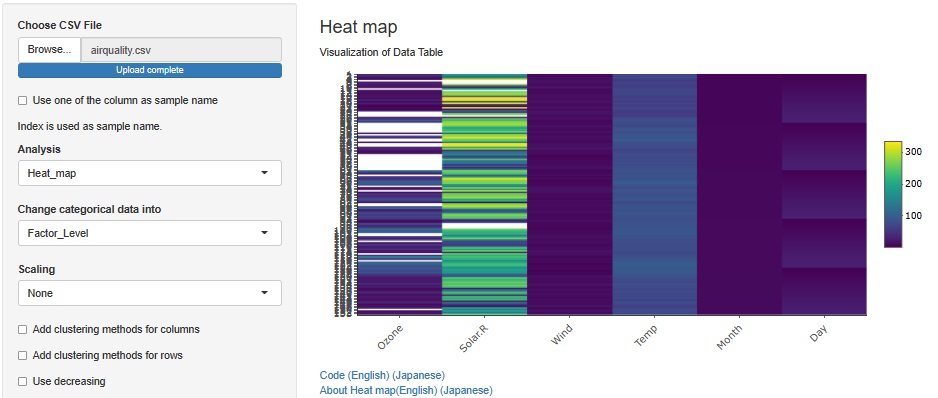
欠損値は、白くなっています。 どこかに集中という訳でもないようですが、完全にばらばらではないです。
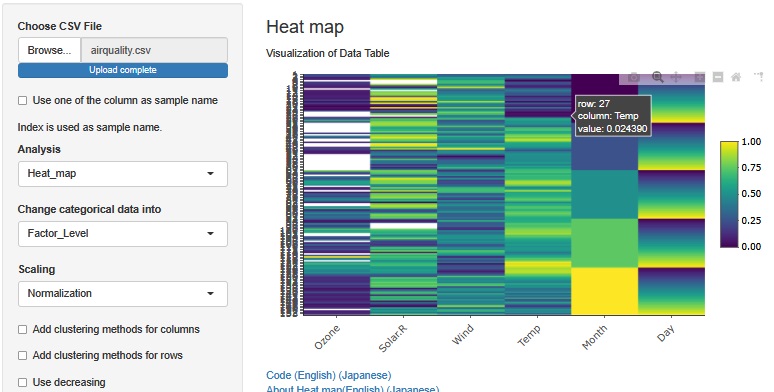
Normalizationで使う統計量は、欠損値ではないデータを使って作っています。
Month(月)が順番に小さい順なことと、Day(日)は、その月の中で小さい順になっていることがわかります。 つまり、このデータは、日付の順に並んでいて、このまま時系列データとして扱えます。
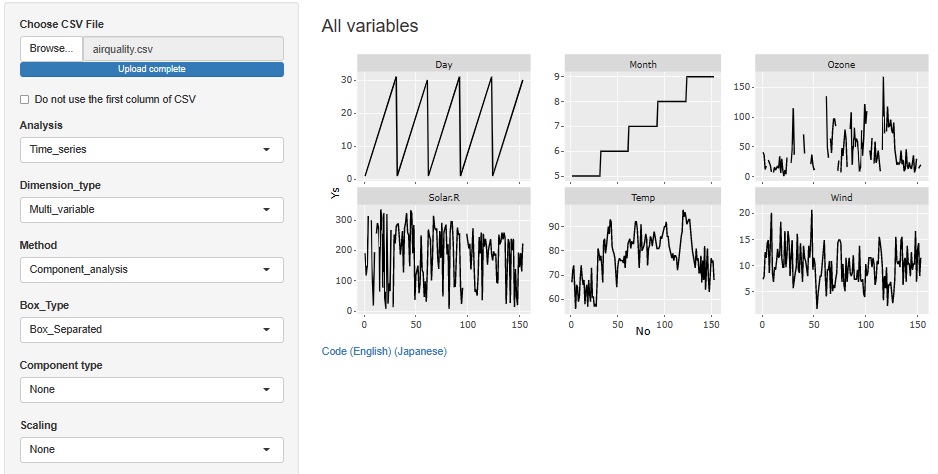
変数別の折れ線グラフでは、ヒートマップで気付いたことだけでなく、欠損値が含まれている変数の具体的な数値が見えます。 このデータの場合は、日付の順にデータが並んでいるので、折れ線は変化の仕方を表しています。
なお、データの表全体を眺めるのなら、ヒートマップが良いので、この方法とヒートマップは、お互いを補完する使い方になります。
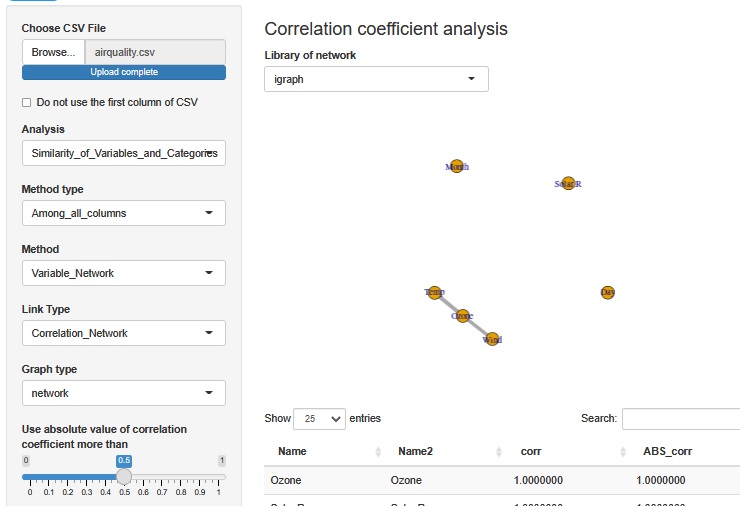
相関係数を見ます。 欠損値があるサンプルは除いて計算されています。
まず、Solar.R(日射量)とDay(日)とMonth(月))は、どれとも相関がないことがわかります。 Ozone(オゾン量)は、Wind(風力)とTempのそれぞれと相関関係があることがわかります。
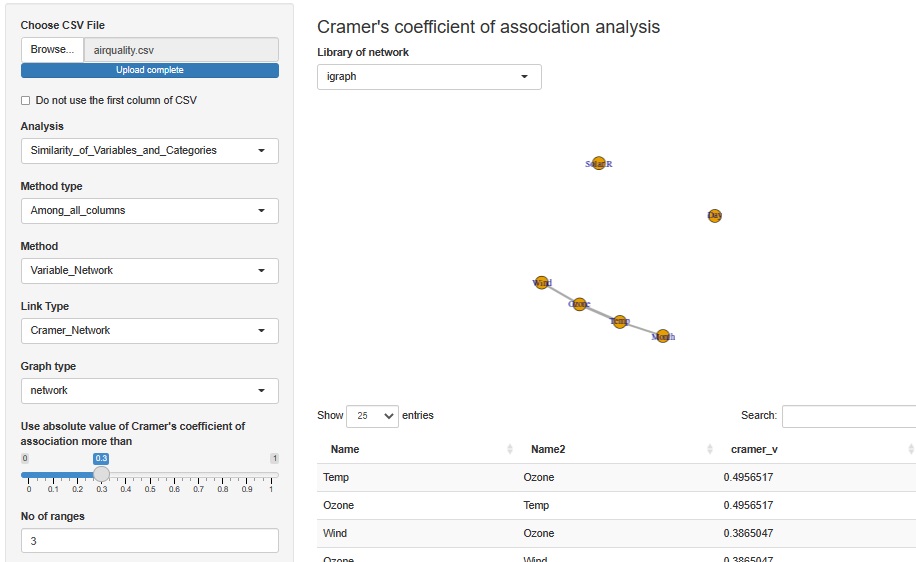
クラメールの連関係数を使って相関関係を分析します。 この例だと、変数毎に区間を3つに分けて、質的変数に変換しています。 欠損値は、欠損値だけで「NA」というカテゴリとなります。
まず、Solar.R(日射量)とDay(日)は、どれとも相関がないことがわかります。 Temp(温度)とMonth(月)に相関があるのは、常識的にもわかりやすい結果です。 Ozone(オゾン量)は、Wind(風力)とTempのそれぞれと相関関係があることがわかります。
Wind(風速)と、Ozoneの関係というのは、Windが速いと空気の入れ替わりが起きるので、Ozoneができる化学反応が進みにくいということかもしれません。
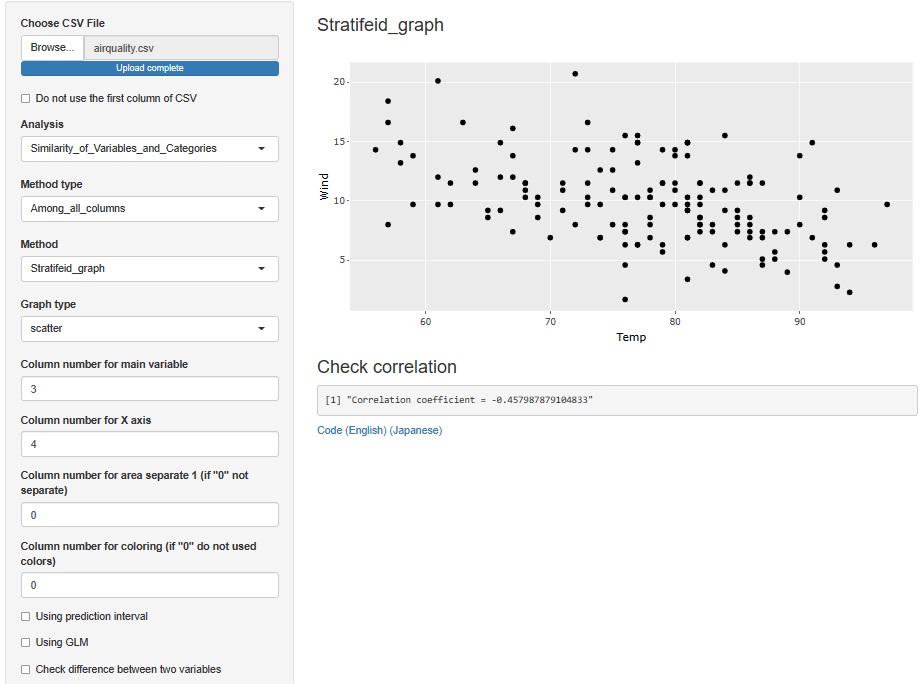
Ozoneにつながっていた、TempとWindだけで散布図を作ってみます。 負の相関があるようにも見えますが、これくらいの関係だと、関係ないと思った方が良さそうです。
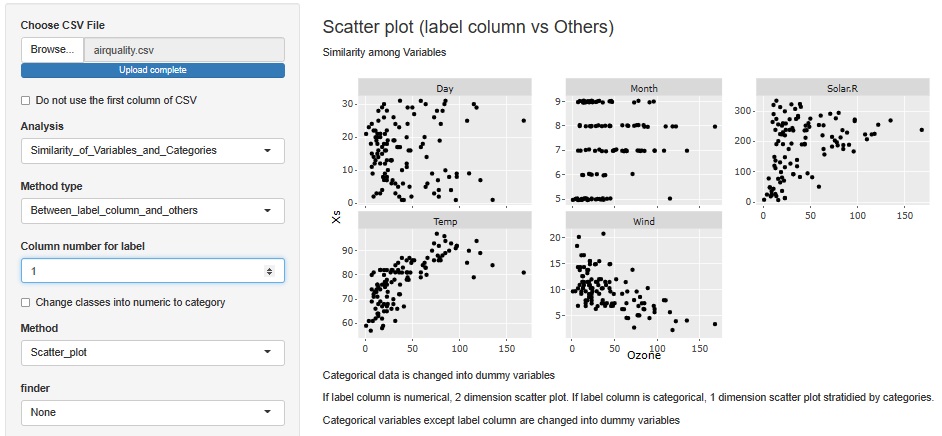
Ozoneを横軸にして、他のすべての変数を縦軸にしてみます。 すると、Tempとは正の相関関係、Windとは負の相関関係があるらしいことがわかります。 Solar.Rとは、単純な正の相関関係ではないですが、少なくともSolar.Rが大きい時に、Ozoneが大きい値が出ていることがわかります。
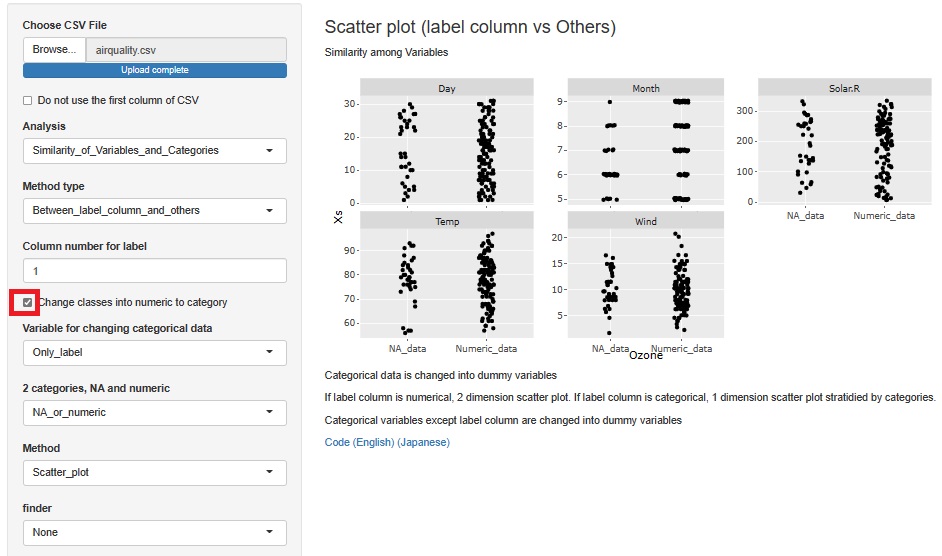
1つ前の分析画面で、「Change classes into numeric to category」にチェックを入れます。 すると、横軸は、NA_data(欠損値)、とNumeric_data(数値データ:欠損値ではないデータ)」に分かれます。
Ozoneの欠損値の出方は、他の変数と特に関係がないです。
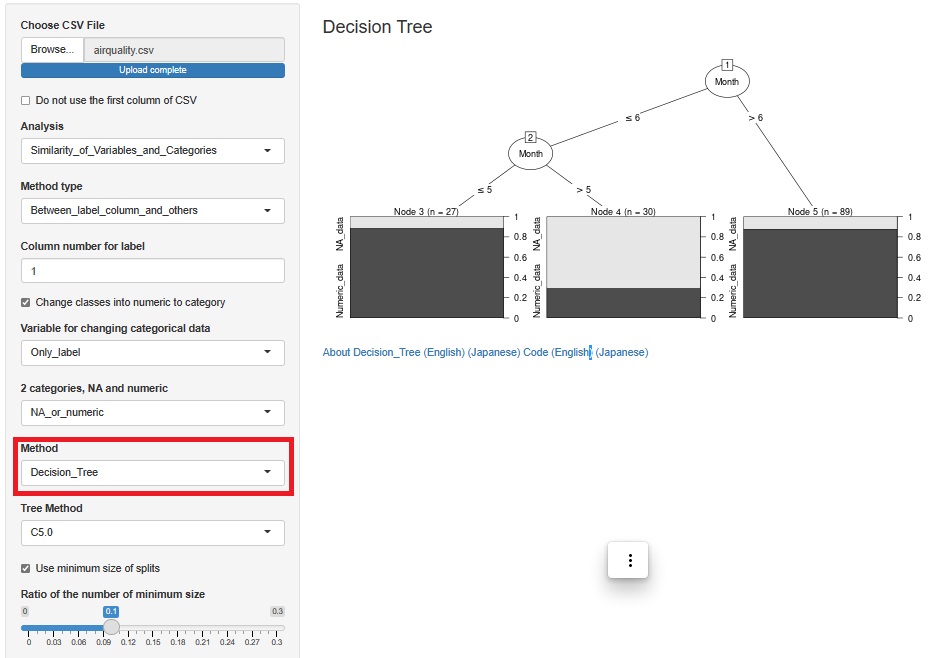
ひとつ前の分析画面で、「Method」をDecision_Tree(決定木)にしてみます。
すると、「≦6」で「>5」のMonth、つまり6月は、NA_dataの割合が多いことがわかります。 ひとつ前の分析の散布図を見ると、たしかに6月はNA_dataの方がプロットが多いです。
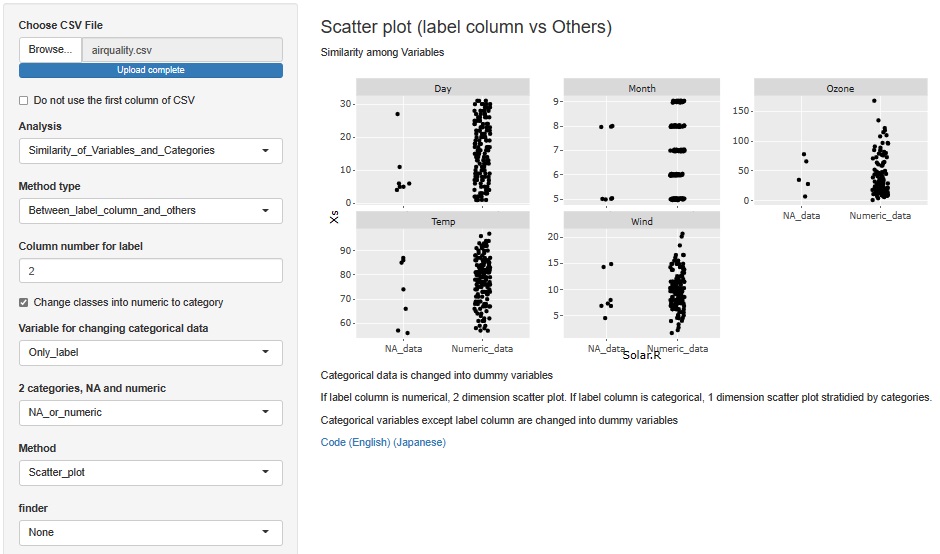
今度は、横軸を「Solar.R」にします。
Monthは、5月と8月だけなことがわかります。 また、Dayは月の前半に比較的多いことがわかります。
Temp、Wind、Solap.Rの3変数で、Ozoneを説明できるかを見ます。
まず、データから、MonthとDayを削除したcsvファイルを作ります。 ここでは、「aiaquality2.csv」という名前にしています。
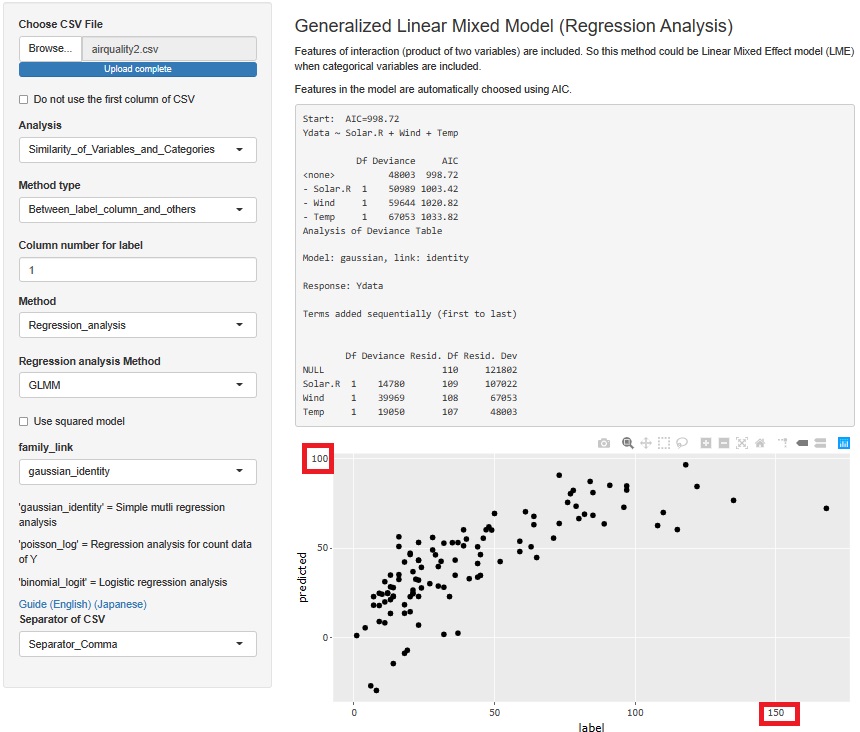
GLMM(一般化線形混合モデル)で、「family_link」を「gaussian_identity」にすると、一般的な重回帰分析になります。
横軸から見ると、元のデータのOzoneは0から170くらいまでの数字があるのに、縦軸は100までしか数字がありません。 そのため、数値的な大小関係はだいたい合っていますが、いまいちな予測モデルになっています。
ちなみに、R-EDA1では、GLMMを「glm」という関数で実行しています。 この関数は、欠損値が含まれていてもエラーが出ずに実行されます。 欠損値が含まれているサンプルは使わずにモデルを作るようです。 説明変数に欠損値「NA」が含まれているサンプルは、予測値は「NA」になります。
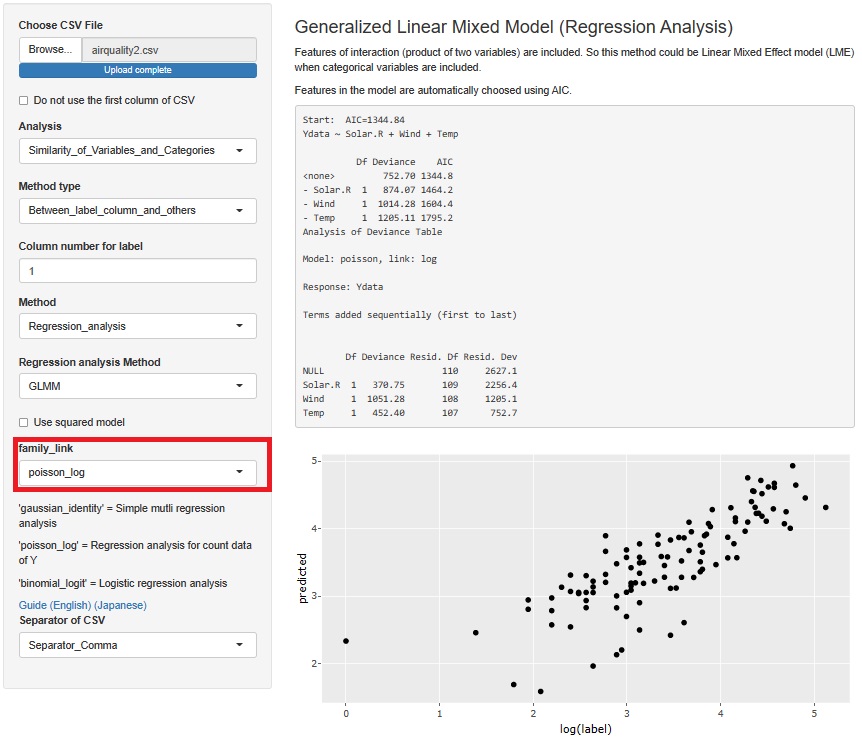
GLMM(一般化線形混合モデル)で、「family_link」を「poisson_log」にすると、ポアソン分布を仮定した回帰分析になります。
この場合は、データの範囲も縦軸と横軸でほぼ同じですし、Y切片を0にした一直線からばらつく感じになっています。 この方が、予測モデルとして良いようです。
ポアソン回帰分析の方が良い理由は、Solar.Rが大きいと、Ozoneの平均値と分散の両方が大きくなっている性質を扱うのに、 このモデルが適していたからではないかと思います。
これ以上、どのモデルが良いのかを検討するのでしたら、データの測定方法や、Ozone発生のメカニズムの仮説が必要で、 データサイエンスというより、サイエンスの領域です。
R Documentation
airqualityのデータの詳しい説明があります。
https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/airquality.html
RPubs by RStudio
airqualityのデータの詳しい説明と、基本的な分析の結果があります。
https://rpubs.com/shailesh/air-quality-exploration

