 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
大量に同じ物を作る場所では、物のばらつきを少しでも小さくしようとします。 品質学 では、「ばらつき」が重要な評価指標になります。 ばらつきの指標の代表的なものが、 標準偏差 です。
長い説明になりますので、結論から書いてしまいます。
「平均値の大小を評価する時には、n数は5位で十分な事が多い。
標準偏差の大小を評価する時には、n数はひと桁多い位、つまり、n数は50位必要な事が多い。」
、というのが結論です。
なお、このページは、
「標準偏差を使ってばらつきを評価する時に、n数に注意する事が重要」
、という話です。
この話は、他の指標でも同じ事が言えます。
平均値の信頼区間
と同じように、分散にも信頼区間の計算式があります。
Excelの関数を使うなら、
95%信頼区間の場合、
上側 = (n-1) * 分散 / CHIINV(0.975,n-1)
下側 = (n-1) * 分散 / CHIINV(0.025,n-1)
で求まります。
上の式の「0.975」と「0.025」という数字は、
95%という数字から、
0.975 = 1 - (1 - 0.95) / 2
0.025 = (1 - 0.95) / 2
、という式を使って導いています。
標準偏差の信頼区間というのは、筆者は文献を知らないのですが、
ここでは、
分散 = 標準偏差の2乗
と考える事で、求める事にします。
Excelの関数を使うなら、95%信頼区間の場合、
上側 = SQRT((n-1) * 標準偏差^2 / CHIINV(0.975,n-1))
下側 = SQRT((n-1) * 標準偏差^2 / CHIINV(0.025,n-1))
で求まります。
SQRTは、ルートを計算するための関数です。
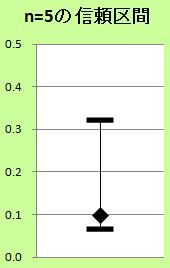 右の図は、
右の図は、
「n=5のデータを計算して、標準偏差が0.1だった時に、信頼区間は、0.07から0.32になる。」、
という事を表しています。
つまり、n=5程度では、標準偏差が0.1と0.2の違いを議論する事は、有意義ではない事になります。
0.1は0.2の半分ですから、これらの数字だけを見ると、大きな違いがありそうです。 そのため、「大きな違いとは言えない」という事がわかるのは、ありがたい情報になります。
工程能力 は、標準偏差を使って計算しますので、n数が重要なのは、工程能力の評価でも同じです。
筆者の経験では、平均値の差を 検定 する時は、n=5で十分な事が多いです。 このn数の感覚で標準偏差も解析しようとすると、 「データからは何もわからない」、「計算するたびに値が大きく変わる」、等で困る事になります。
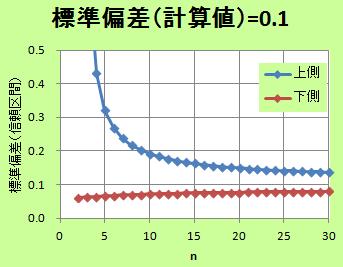 右の図は、
右の図は、
「標準偏差が0.1だった時に、n数が違うと信頼区間はどのくらい変わるのか」、
という事を表しています。
この図からは、「n数は10以上は必要」と言えそうです。
また、n数が20と30では、得られる効果があまり変わらない事もわかります。 つまり、どんなにn数を増やしても、標準偏差が、0.010と0.012くらいの違いは、「意味のある違い」とは言えないです。
標準偏差が0.1くらいの時は、上記のように、n数は10でも良さそうです。 しかし、実務上は、もっと必要になる事があります。
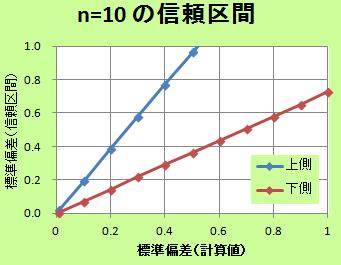 もうひとつの図は、
もうひとつの図は、
「n数は10で同じ時に、標準偏差の計算値が変わると、信頼区間はどうなるのか」、
を表しています。
標準偏差が大きくなると、信頼区間の幅もどんどん大きくなります。
例えば、「計算した標準偏差が0.6だとすると、真の値は1.0かもしれない。」、
という事を表しています。
まとめると、標準偏差が0.1から0.6くらいの大きさのグループがいくつかある場合、 n数が10程度で計算した標準偏差なら、「これらのグループには、ばらつきの違いがある」と思うのは、 あまり意味がありません。
別の見方をすれば、n数が数十程度では、 標準偏差が0.1や0.2程度違う事を議論するのは、有意義ではありません。
また、筆者の経験の範囲ですが、標準偏差を議論する時は、n数は30でも不安です。 できれば、100位は欲しいところです。
順路
 次は
二重測定(対応のあるデータ)の使い道
次は
二重測定(対応のあるデータ)の使い道
