Since "high dimension" is a relative term, we do not say "high dimension above 0 dimension", but when there are relatively many columns of data, we call it "high dimension" on this site. is.
By the way, "higher dimension" is sometimes called "multidimensional", but "lower dimension" does not seem to be called "smaller dimension". "Higher dimensions" are also sometimes referred to as "multivariates" or "multivariables".
High-dimensional data and many columns of data are not necessarily the same, but can be confused. Distinguishing and consciousness expands the range of data science .
The content of this part overlaps with the page of spatiotemporal data .
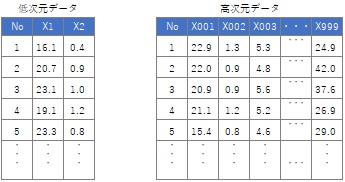
When converting plane information into data, first, it will be as No. 1 or No. 2 in the figure below. Each is shaped like the high-dimensional data at the beginning. However, as it is, methods such as multivariate analysis for investigating and classifying the differences between planes cannot be used.
Therefore, if you make strips in the vertical and horizontal directions and connect them into one, you can use various methods. The dimension in this case is the coordinates of each grid. The point is that the order of the columns is meaningful. In general multivariate analysis methods, the algorithm does not care about the order of columns, so close grid relationships are not considered.
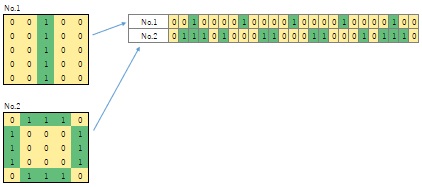
I think that a typical example of plane data is an image. In the case of the author, there was a time when I was dealing with data in which silicon wafers were divided into grids and inspected, but there is also data on such planes.
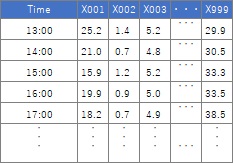
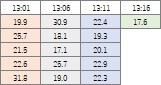
In the case of time series data, there are two types of high-dimensional data. The first is the data that is in the form of high-dimensional data at the beginning. The data in the same row is the data at the same time.
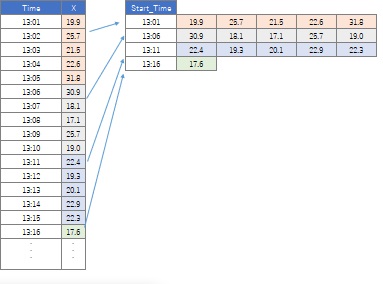
The second is when the original data is one-dimensional data.
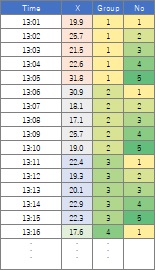
If you divide the time series data into intervals and rearrange them, you will get the form of high-dimensional data. One section is one line of the data at the beginning. The dimensions in this case are the order from the beginning of the delimiter. The order of the columns makes sense.
As for the second form, factory data often do not have a fixed length. Therefore, not only is it high-dimensional, but the number of dimensions is different for each row, which makes the data difficult to handle.
The type of data in which the rows and columns of the second data form are swapped is called 1.5th-order data on this site . If you want to analyze with a line graph, you need to make it in the form of 1.5th order data. Note that it cannot be handled as high-dimensional data in the form of 1.5th-order data.
Although it is in the state before it becomes high-dimensional data, it is possible to create three-dimensional data by using the method of creating metaknowledge data. This format is convenient because the number of dimensions does not vary from row to row.
NEXT  Money data
Money data
