Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
対数尤度情報量分析 を計算します。
基本的に質的変数を扱う方法ですが、量的変数は
1次元クラスタリング
の方法で、質的変数に変換するコードが入っているので、
質的・量的が混合していたり、量的変数だけでも使えるようにしてあります。
library(vcd)
setwd("C:/Rtest")
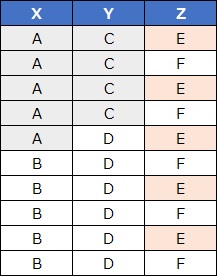
Data <- read.csv("Data.csv", header=T)
Data1 <- Data # 1次元クラスタリングの出力先を作る
n <- ncol(Data1)
for (i in 1:n) {
if (class(Data1[,i]) == "numeric") {
Data1[,i] <- droplevels(cut(Data1[,i], breaks = 3,include.lowest = TRUE))# 3分割する場合。量的データは、質的データに変換する。
}
}
LllMatrix <- matrix(0,nrow=n,ncol=n)
rownames(LllMatrix)<-colnames(Data1) # 行名をつける
colnames(LllMatrix)<-colnames(Data1) # 列名をつける
for (j1 in 1:n) {
for (j2 in 1:n) {
if(j1 >= j2){
TableXY <- table(Data1[,j1], Data1[,j2])# 分割表の作成
Pxy <- TableXY
for (i in 1:nrow(TableXY)) {
Pxy[,i] <- TableXY[,i] / sum(TableXY[,i])
}
Lllxy <- TableXY * log(Pxy,2)
Lllxy[is.na(Lllxy)] <- 0
Pyx <- TableXY
for (i in 1:nrow(TableXY)) {
Pyx[i,] <- TableXY[i,] / sum(TableXY[i,])
}
Lllyx <- TableXY * log(Pyx,2)
Lllyx[is.na(Lllyx)] <- 0
LllMatrix[j1,j2] <- sum(Lllyx)
LllMatrix[j2,j1] <- sum(Lllxy)
}
}
}
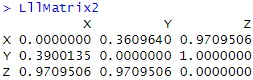
LllMatrix# 対数尤度行列
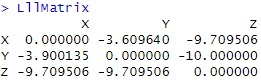
LllMatrix2 <- -LllMatrix / nrow(Data1)
LllMatrix2# 対数尤度情報量行列