Pythonによるデータ分析 |
Excelによるヒートマップ |
Rによるヒートマップ
Pythonによるデータ分析 |
Excelによるヒートマップ |
Rによるヒートマップ
Pythonによるデータ分析 |
Excelによるヒートマップ |
Rによるヒートマップ
Pythonによるデータ分析 |
Excelによるヒートマップ |
Rによるヒートマップ
ヒートマップ は、 テーブルデータ全体の可視化 の一種です。 変数が複数ある時に、とりあえず全部を見てみるための方法です。 データの並び方が、時系列になっていれば、時系列解析になります。
質的変数はダミー変換して、この方法が使えるようにしています。 1列に3つのカテゴリが入っていれば、3列のデータが作られます。
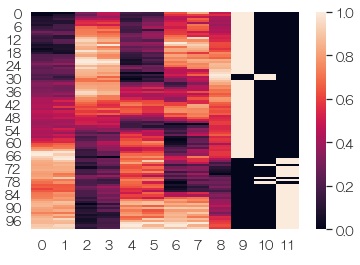
下記の例では、X1〜X9という変数が量的変数で、X10という変数が質的変数です。
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
import matplotlib.pyplot as plt# パッケージの読み込み
import seaborn as sns # パッケージの読み込み
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
sns.heatmap(df2) # ヒートマップを描く
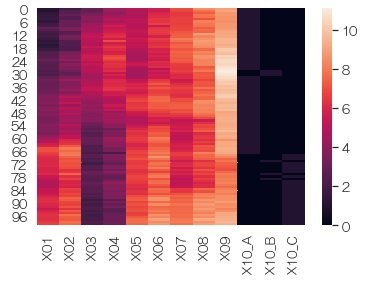
各変数で、平均0、標準偏差1に 標準化 してから、グラフにします。 値が大きく異なる変数が入っている時に、それぞれの変数の様子がよく見えるようになります。
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
import matplotlib.pyplot as plt# パッケージの読み込み
import seaborn as sns # パッケージの読み込み
from sklearn import preprocessing # パッケージの読み込み
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
df3 = preprocessing.scale(df2)# 標準化
sns.heatmap(df3) # ヒートマップを描く
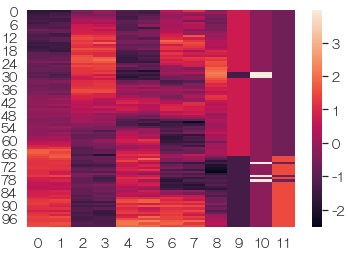
各変数で、最小値0、最大値1に正規化してから、グラフにします。 効果は標準化と似ています。 質的変数が混ざっている場合は、こちらの方が0と1の出方が見やすいです。
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
import matplotlib.pyplot as plt# パッケージの読み込み
import seaborn as sns # パッケージの読み込み
from sklearn import preprocessing # パッケージの読み込み
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
df3 = preprocessing.minmax_scale(df2)# 正規化
sns.heatmap(df3) # ヒートマップを描く