 R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
奜傟抣傗寚懝抣偺偁傞僨乕僞偺夝愅 偺儁乕僕偵偼丄 寚懝抣 偺偁傞僨乕僞偺埖偄曽偑偁傝傑偡偑丄偙偺儁乕僕偼R傪巊偆応崌偺丄傕偭偲嬶懱揑側榖偵側傝傑偡丅
傑偢丄寚懝抣偑偳偺傛偆側宍偱僨乕僞偺拞偵偁偭偰丄偦傟傪R偺拞偱偼偳偺傛偆偵埖偭偰偄傞偺偐偱偡丅
壓偺傛偆偵丄寚懝抣偑暥帤捠傝丄寚懝偟偰偄偰嬻敀偵側偭偰偄傞応崌偲丄寚懝抣偑乽NA乿偲偄偆暥帤楍偵側偭偰偄傞応崌偑偁傝傑偡丅
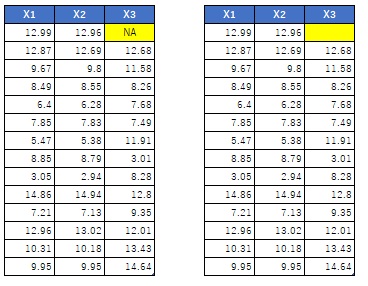
偄偢傟傕丄R偵撉傒崬傓偲乽NA乿偵側傝傑偡丅
summary偱尒傞偲乽NA's :1乿偲側偭偰偄偰丄寚懝抣乮NA乯偲偟偰擣幆偝傟偰偄傞偙偲偑傢偐傝傑偡丅
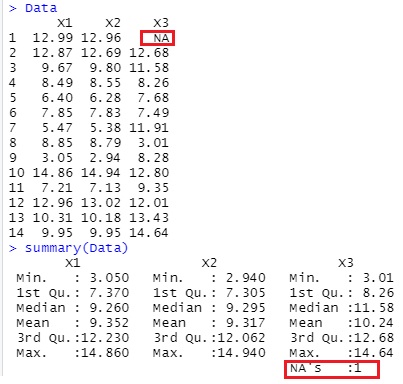
椺奜偑偁傞偐傕偟傟傑偣傫偑丄R偺応崌丄寚懝抣偑娷傑傟偰偄傞検揑曄悢偵懳偟偰丄壗偐張棟傪偟傛偆偲偡傞偲摿暿側埖偄偵側傝傑偡丅
椺偊偽丄憡娭峴楍傪媮傔傞偲丄寚懝抣偑娷傑傟偰偄傞検揑曄悢偲偺憡娭學悢偼乽NA乿偲側傝丄媮傑傝傑偣傫丅
偙偺偨傔丄寚懝抣埲奜偺悢抣傪巊偆偲丄憡娭偑崅偔偰傕傢偐傜側偄偱偡丅
偪側傒偵丄懠偺僜僼僩偩偲丄寚懝抣埲奜偺悢抣傪巊偭偨憡娭學悢偑媮傑傞傛偆偵側偭偰偄傞偙偲傕偁傝傑偡丅
寚懝抣傪偳偺傛偆偵曄姺偡傞偐偱丄暘愅偱偒傞偙偲偑曄傢傝傑偡丅
寚懝抣偑偁傞峴偼彍偄偰偟傑偆応崌偱偡丅
寚懝偟偰偄傞偙偲偵摿偵堄枴偑側偄応崌偼丄庤寉側曽朄偱偡丅 偨偩偟丄偙偺曽朄偱梊應儌僨儖傪嶌偭偨応崌丄梊應偟偨偄抜奒偺僨乕僞偺寚懝抣偑娷傑傟偰偄傞偲丄梊應偑偱偒側偄偱偡丅
Data <- na.omit(Data)
偲偡傞偲丄壓婰偵側傝傑偡丅
寚懝抣偑偱偒偨攚宨傗丄寚懝抣偺埖偄曽偺曽恓偵傛傝傑偡偑丄椺偊偽丄寚懝抣傪乽0乿偲偟偰埖偄偨偄応崌偱偡丅
Data[is.na(Data)] <- 0
偲偡傞偲丄壓婰偵側傝傑偡丅
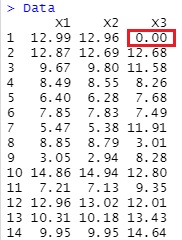
奺曄悢偺寚懝抣傪丄偦偺曄悢偺丄寚懝抣埲奜偺悢抣偺暯嬒抣偵偟偨偄応崌偼丄壓婰偵側傝傑偡丅
for (i in 1:ncol(Data)) {
Data[,i][is.na(Data[,i])] <- mean(Data[,i], na.rm = TRUE)
}
偲偡傞偲丄壓婰偵側傝傑偡丅

R偵傛傞曄悢偺曄姺 偺儁乕僕偵 侾師尦僋儔僗僞儕儞僌 傪徯夘偟偰偄傑偡偑丄偙偺曽朄傪巊偆偲丄乽NA乿偼乽NA乿偲偄偆柤慜偺僇僥僑儕偵側傝丄偦傟埲奜偺悢抣偵懳偟偰丄侾師尦僋儔僗僞儕儞僌偺張棟偑偝傟傑偡丅
椺偊偽丄
Data[,3] <- droplevels(cut(Data[,3], breaks = 3,include.lowest = TRUE))
偲偡傞偲丄壓婰偵側傝傑偡丅
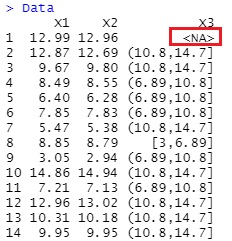
寚懝抣偵側偭偰偄傞棟桼傪丄懠偺曄悢偐傜悇應偡傞偨傔偺曄姺偱偡丅
Data[,3][!is.na(Data[,3])] <- 0
Data[,3][is.na(Data[,3])] <- 1
偲偡傞偲丄壓婰偵側傝傑偡丅
偙偆側偭偰偄傞偲丄寚懝抣偺偁傞曄悢傪
儔儀儖暘椶
偺庤朄偺栚揑曄悢偵偟偰丄寚懝偟偰偄傞偐偳偆偐偲丄懠偺曄悢偺娭學傪挷傋傞偙偲偑偱偒傑偡丅
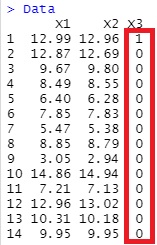
儔儀儖暘椶 偵傛偭偰偼丄栚揑曄悢偑悢抣偱偼偱偒側偄偙偲偑偁傝傑偡偑丄偦偺応崌丄椺偊偽丄忋婰偺乽0乿丒乽1乿傪丄乽A乿丒乽B乿偲偟傑偡丅
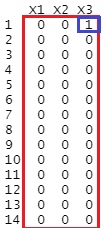
僨乕僞偺拞偵丄寚懝抣偑偳偙偵偳偺傛偆偵擖偭偰偄傞偺偐傪挷傋偨偄帪偺曽朄偱偡丅 慡晹偺曄悢偵偮偄偰丄寚懝抣側傜偽1丄寚懝抣埲奜偼0偵偟傑偡丅
Data[!is.na(Data)] <- 0
Data[is.na(Data)] <- 1
偲偡傞偲丄壓婰偵側傝傑偡丅
biostatistics
抲姺傗嶍彍偵偮偄偰丄忋婰埲奜偺僐乕僪傕徯夘偟偰偄傑偡丅
https://stats.biopapyrus.jp/r/basic/nan.html
