Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
クラスターの予測の分析 のRによる実施例です。
Rを使ったクラスター分析の実施例になります。 クラスター分析の手法は、いろいろありますが、共通部分は一緒に書いています。
下記は、コピーペーストで、そのまま使えます。 下記のコードを使った場合、X-means以外は、このページの一番上にある色分けのグラフと同じ結果になります。 この例では、入力データは量的データになっていることを想定しています。 質的データがあるとエラーになります。
以下に、複数の方法がありますが、入力データの作り方は同じなので、ここにまとめています。
この例では、Cドライブの「Rtest」というフォルダに、 「Data1.csv」という名前でデータが入っている事を想定しています。
入力データの読み込みをします。
Data10からData11への変換は、すべての列を0と1の間のデータにするためのものです。
DBSCANをする時はあった方が良いですし、どの手法だとしても、身長と体重など、単位が違う変数が混ざっている場合は必須です。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data1 <- read.csv("Data1.csv", header=T) # データを読み込み
Data10 <- Data1[,1:2]## クラスター分析に使うデータを指定。ここでは1〜2列目の場合
Data11 <- Data10 # 出力先の行列を作る
for (i in 1:ncol(Data10)) { # ループの始まり。データの列数を数えて同じ回数繰り返す
Data11[,i] <- (Data10[,i] - min(Data10[,i]))/(max(Data10[,i]) - min(Data10[,i]))
} # ループの終わり
library(mclust) # ライブラリを読み込み
mc <- Mclust(Data11,3) # 混合分布で分類。これは3個のグループ分けの場合
output <- mc$classification # 分類結果の抽出
混合分布の場合は、データの分類だけではなく、他のデータがあった時に、分類に使ったデータからわかった分類のどれに該当するのかの予測ができます。
これは、
予測のためのソフトの使い方
と同じです。
Data2 <- read.csv("Data2.csv", header=T) # テストデータを読み込み
for (i in 1:ncol(Data2)) { # ループの始まり。データの列数を数えて同じ回数繰り返す
Data21[,i] <- (Data2[,i] - min(Data10[,i]))/(max(Data10[,i]) - min(Data10[,i]))
} # ループの終わり
output2 <- predict(mc, Data21) # テストデータの分類を作成
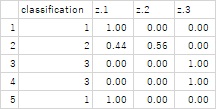
ファイルに出力した内容の例が下の表になります。
最終的に、3つのグループのどれになるのかを予測しただけではなく、それぞれのグループに属する確率がわかるようになっています。