Analysis of hidden variables with Python
This is a recipe for exploring hidden variables in Python.
I wanted to search for a hypothesis by correlation as a causal inference , and I analyzed the similarity of variables with Python, but sometimes I can't find any correlation between the variable of interest and other variables.
The method on this page is a way to explore further data without giving up at such times.
There are two methods, principal component analysis and independent component analysis , but sometimes the results are similar, and sometimes either is better.
The method using principal component analysis has no parameter settings and the calculation time is shorter. In principal component analysis, it seems better to try independent component analysis when hidden variables are not found.
If the variable of interest is a quantitative variable
The variable that the code below is paying attention to is "Y". There are no rules about how to name other variables.
How to use principal component analysis
import os #
import pandas as pd #
import matplotlib.pyplot as plt#
import seaborn as sns #
from sklearn import preprocessing #
from sklearn.decomposition import PCA#
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') #
os.chdir("C:\\PyTest") #
df= pd.read_csv("Data.csv" , engine='python')#
df11 =pd.DataFrame(df['Y'])#
df12 = df.drop('Y', axis=1)#
df2 = pd.get_dummies(df12)#
df3 = preprocessing.scale(df2)#
df3 = pd.DataFrame(df3, columns = df2.columns.values)#
pca = PCA()#
pca.fit(df3)#
df4 = pd.DataFrame(pca.transform(df3), columns=["PC{}".format(x + 1) for x in range(len(df3.columns))])#
df5 = pd.concat([df11,df3, df4], axis = 1)#
df6 = pd.melt(df5, id_vars=['Y'])#
sns.relplot(data=df6, x='value', y='Y', col='variable',kind='scatter',col_wrap = 3) #
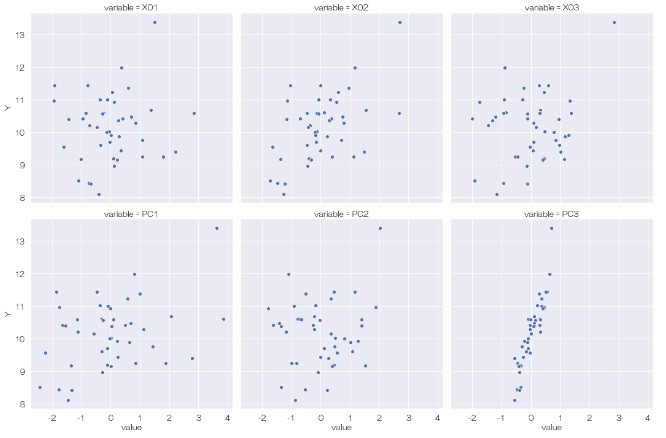
Looking at this result, we first see that there is no correlation between Y and the other variables in the original data (X01, X02, X03). Next, looking at the relationship between Y and the principal component, we can see that there is a correlation between Y and PC3. It looks like a hidden variable.
After this, we'll look at which of the original variables the hidden variable affects.
df7 = pd.DataFrame(pca.components_ ,columns = [df.columns],index = ["PC{}".format(x+1) for x in range(len(df.columns))])#
sns.clustermap(df7, method='ward', metric='euclidean') #
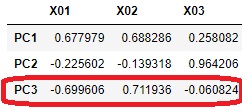
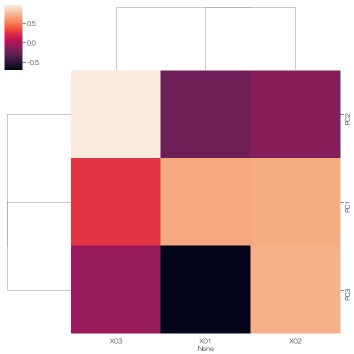
Looking at this result, it was found that the hidden variable PC3 does not seem to affect X03 because the absolute value of the factor loading is close to 0 for X03 and PC3. PC3 seems to be a factor that seems to have a slight effect on X01 and X02.
How to use Independent Component Analysis
import os #
import pandas as pd #
import matplotlib.pyplot as plt#
import seaborn as sns#
from sklearn import preprocessing #
from sklearn.decomposition import PCA#
from sklearn.decomposition import FastICA#
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') #
os.chdir("C:\\PyTest") #
df= pd.read_csv("Data.csv" , engine='python')#
df11 =pd.DataFrame(df['Y'])#
df12 = df.drop('Y', axis=1)#
df2 = pd.get_dummies(df12)#
df3 = preprocessing.scale(df2)#
df3 = pd.DataFrame(df3, columns = df2.columns.values)#
pca = PCA()#
pca.fit(df3)#
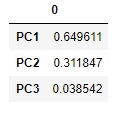
pd.DataFrame(pca.explained_variance_ratio_, index=["PC{}".format(x + 1) for x in range(len(df3.columns))])#
ICA = FastICA(n_components=3, random_state=0)#
ICA.fit(df3)#
df4 = pd.DataFrame(ICA.transform(df3), columns=["IC{}".format(x + 1) for x in range(len(df3.columns))])#
df5 = pd.concat([df11,df3, df4], axis = 1)#
df6 = pd.melt(df5, id_vars=['Y'])#
sns.relplot(data=df6, x='value', y='Y', col='variable',kind='scatter',col_wrap = 3)#
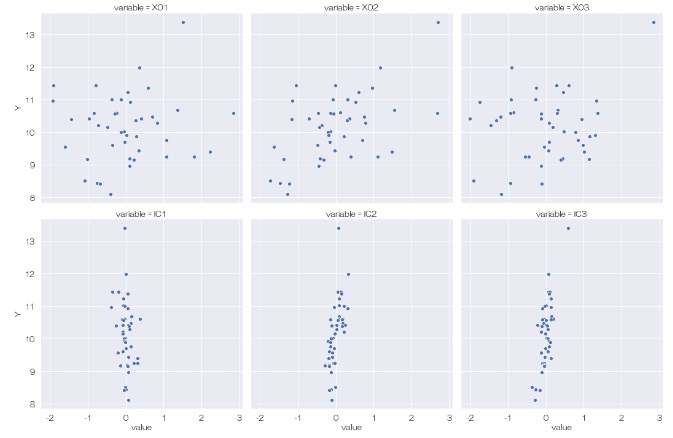
Looking at the relationship between Y and the independent component, it looks like there are no hidden variables.
After this, I'd like to find out which of the original variables the hidden variable affects, but I don't know how to do it like in principal component analysis. I will add it here when I understand it.
If the variable of interest is a qualitative variable
How to use principal component analysis
import os #
import pandas as pd #
import matplotlib.pyplot as plt#
import seaborn as sns #
from sklearn import preprocessing #
from sklearn.decomposition import PCA#
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') #
os.chdir("C:\\PyTest") #
df= pd.read_csv("Data.csv" , engine='python')#
df11 =pd.DataFrame(df['Y'])#
df12 = df.drop('Y', axis=1)#
df2 = pd.get_dummies(df12)#
df3 = preprocessing.scale(df2)#
df3 = pd.DataFrame(df3, columns = df2.columns.values)#
pca = PCA()#
pca.fit(df3)#
df4 = pd.DataFrame(pca.transform(df3), columns=["PC{}".format(x + 1) for x in range(len(df3.columns))])#
df5 = pd.concat([df11,df3, df4], axis = 1)#
df6 = pd.melt(df5, id_vars=['Y'])#
sns.boxplot(data=df6, x='variable', y='value', hue='Y') #
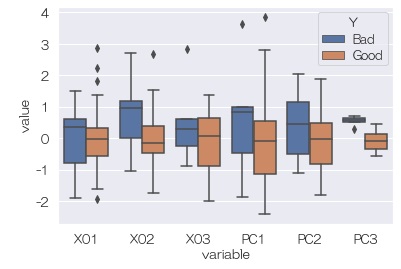
Next, looking at the relationship between Y and principal components, Y is fairly clearly separated in PC3. It looks like a hidden variable.
Finding out which of the original variables the hidden variable affects is the same as when using principal component analysis when the variable of interest is a quantitative variable.
How to use Independent Component Analysis
import os #
import pandas as pd #
import matplotlib.pyplot as plt#
import seaborn as sns #
from sklearn import preprocessing #
from sklearn.decomposition import PCA#
from sklearn.decomposition import FastICA#
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') #
os.chdir("C:\\PyTest") #
df= pd.read_csv("Data.csv" , engine='python')#
df11 =pd.DataFrame(df['Y'])#
df12 = df.drop('Y', axis=1)#
df2 = pd.get_dummies(df12)#
df3 = preprocessing.scale(df2)#
df3 = pd.DataFrame(df3, columns = df2.columns.values)#
pca = PCA()#
pca.fit(df3)#
pd.DataFrame(pca.explained_variance_ratio_, index=["PC{}".format(x + 1) for x in range(len(df3.columns))])#
ICA = FastICA(n_components=3, random_state=0)#
ICA.fit(df3)#
df4 = pd.DataFrame(ICA.transform(df3), columns=["IC{}".format(x + 1) for x in range(len(df3.columns))])#
df5 = pd.concat([df11,df3, df4], axis = 1)#
df6 = pd.melt(df5, id_vars=['Y'])#
sns.boxplot(data=df6, x='variable', y='value', hue='Y')#
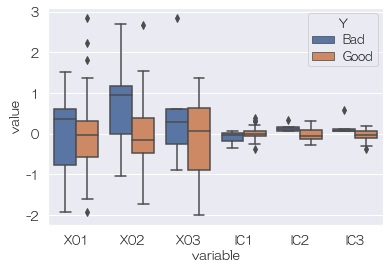
Looking at the relationship between Y and the independent component, it looks like there are no hidden variables.
