2次データ をPythonで作る場合です。
まず、表の
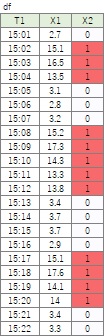
1次データ
があるとします。
X2が1の時は機械が動作中で、0の時が停止中とします。
下記のPythonのコードを使って、3つの特徴量の2次データを作る例になります。
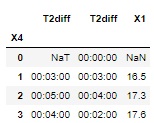
左のT2diffが、X2が1の時のグループ毎の時間です。
右のT2diffが、X2が0の時のグループ毎の時間です。
X1は、X2が1の時のX1の最大値です。
変数名は本当は変えた方が良いですが、コードが煩雑になるので、ここでは触れていません。
groupbyによる、最大値や平均値等の統計量を計算が、一番簡単な特徴量と思います。
groupbyによる時間の計算は、sumを使う点が「なぜ?」となるかもしれませんが、理屈がわかれば簡単に計算できます。
実際の特徴量としては、「ピーク(最大値)になるまでの時間」、「2番目のピークの値」、「ある変数がピークになった時の、別の変数の値」、 といったものが欲しいことがあります。 2次データ作成のサンプル(Excel編) の場合は、データの上からの処理を具体的に自分で書くので、このような特徴量を作りこむことはやりやすいです。 Pythonの場合は、Excelの時と同じようなコードを作るか、下記のX3のような変数をうまく作って短いコードで出せるようにするか、 の2つの方向性があります。 前者の方がやりたいことを確実にできるようになりますが、コードを書くのがそれなりに手間です。 後者はアイディアが出るかにかかっています。
Pythonのコードは下記になります。 最後の行の「df2」が、2次データの表になります。
import pandas as pd # パッケージの読み込み
df= pd.read_csv("Data.csv" , engine='python')# データを読み込む
df['X3']=df.X2.diff() # フラグ(X2)の差分のデータを作る
df['X4'] = (df['X3'] == 1).cumsum() # 差分のデータが「1」の時に累積する
df['X5']=df.groupby('X4').cumcount()+1 # グループ変数を作る
df['T2']=pd.to_datetime(df['T1']) # 時刻データを作る
df['T2diff']=df.T2.diff() # 時刻(T2)の差分のデータを作る
#この下から、2次データの作成
df21=df[df.X2 == 1].groupby(['X4']).T2diff.sum() # グループ毎の差分の合計値を計算することで、X2が1の時の時間を計算
df20=df[df.X2 == 0].groupby(['X4']).T2diff.sum() # 同じく、X2が0の時の時間を計算
df31=df[df.X2 == 1].groupby(['X4']).X1.max()# グループ毎に、X2が1の時のX1の最大値を計算
df2 = pd.concat([df21, df20,df31], axis=1)# グループ毎の計算値をひとつの表にまとめる。
このコードは、大きく2つに分かれています。
前半は元のデータ「df」に列を追加していくものです。
1行ずつの詳しい説明は、
メタ知識のデータの作成
にあります。
最終的には、dfは、下のようになります。
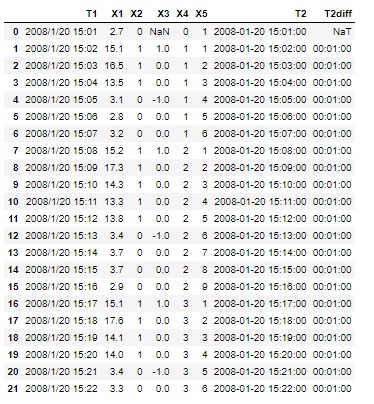
このdfの段階で
1.5次データの解析
ができるようになります。
後半は、groupbyを使って、グループ毎の集計になります。
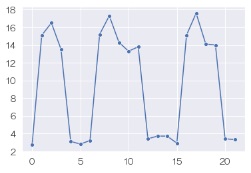
ちなみに、 このページのグラフは、 seaborn で作っています。
順路
 次は
3次データの解析
次は
3次データの解析
 Tweet
Tweet
