seabornには、Pythonで美しいグラフを簡単に描くことができる特徴と、 様々なグラフを簡単に描くことができる特徴があります。
このページは、 グラフィカル分析 に使うための使い方になります。 seabornでは、好みの配色にしたりもできますが、それには触れていません。
PandasのPlot (matplotlib)は、たくさんの変数をいっぺんにグラフ化して比べる事が簡単にできます。 しかし、層別のグラフ を作るのは、簡単ではありません。
ggplot2 は、簡単な事と、簡単ではない事が、matplotlibと逆です。
seabornは、 PandasのPlot を使いつつ、ggplot2のようなこともできるソフトです。
2020年の3月の時点では、 seabornにはいまいち安定しない機能があるものの、 それは PandasのPlot では安定して使える状況のようです。 作りたいグラフに応じて、両者の機能から欲しいものを持ってくる使い方が良いようです。
使用例は下記になります。
下記は、コピーペーストで、そのまま使えます。 この例では、グラフを描くためのPythonのプログラムが保存されているフォルダと同じ所に、 「Data.csv」という名前でデータが入っている事を想定しています。
「sns」から始まる命令文の前に、下記は必ず必要です。
import pandas as pd # パッケージの読み込み
import matplotlib.pyplot as plt# パッケージの読み込み
import seaborn as sns # パッケージの読み込み
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
df= pd.read_csv("Data.csv" , engine='python')# データを読み込む
データ全体を見るためのグラフ
・全部の量的変数のヒートマップ
たくさんの変数を見るためのグラフ
・全部の量的変数の1次元分布の比較
・全部の量的変数のサンプル順の折れ線グラフ
・全部の量的変数の組み合わせ
2つの量的変数の関係を詳しく調べるためのグラフ
・基本の折れ線グラフ
・層別の折れ線グラフ
・信頼区間の折れ線グラフ
・基本の散布図
・層別の散布図
・回帰線
・ジョイントプロット
・6角形の2次元ヒストグラム
・密度分布
ヒストグラム
・基本のヒストグラム
・層別のヒストグラム
・区切りの良い区間のヒストグラム
1つの量的変数の分析のためのグラフ
・1つの量的変数のグラフ
・1つの量的変数を1つの質的変数で分解するグラフ
・1つの量的変数を2つの質的変数で分解するグラフ
・1つの量的変数を3つの質的変数で分解するグラフ
棒グラフ
・普通の棒グラフ
・統計量の棒グラフ
・頻度グラフ
備忘録
・グラフのサイズ
・データの順番の影響
・日本語の文字化け
・グラフがない
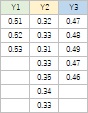
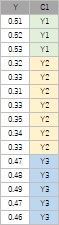
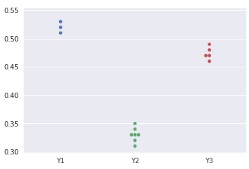
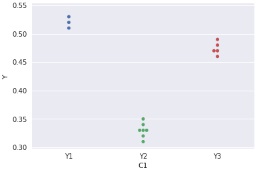
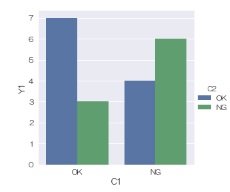
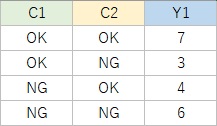
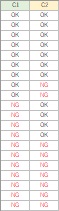
データの表を2つ並べましたが、
左のデータについて、
全部の量的変数の1次元分布の比較
を使ったのが左のグラフです。
右のデータについて、
1つの量的変数を1つの質的変数で分解するグラフ
を使ったのが右のグラフです。
ほぼ同じになります。
左の表の形は、各列で、データの数が同じでなくても良いことがポイントです。
データの集計の仕方によっては、 データ分析のスタートには両方の表の形がありますが、簡単なグラフを作るのでしたら、どちらかの形に作り直さなくても良いことがあります。
全部の量的変数について、 ヒートマップ にすることができます。
なお、質的変数が混ざっているとエラーになります。
sns.heatmap(df) # ヒートマップを描く
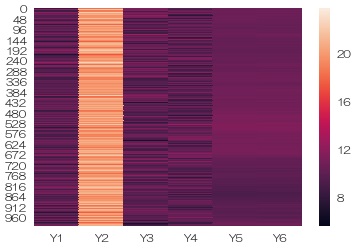
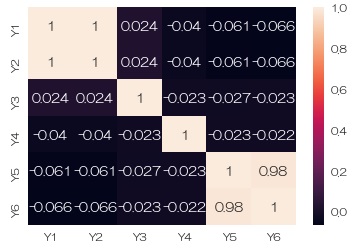
Y2の値が他に比べて極端に高いことがわかります。 また、Y5とY6はほぼ同じデータが入っていることがわかります。
値の低い方の変化をはっきりと見るために、色の範囲を8から12にしてみます。
sns.heatmap(df,vmin=8,vmax=12) # 色の範囲を指定してヒートマップを描く
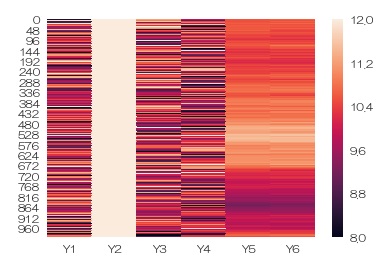
Y2とその他の値が極端に違うので、 Y2以外に合わせて色の範囲を指定すると、Y2の変化がまったくわからなくなりました。
範囲の指定は、グラフを見やすくする対策のひとつになるのですが、 今度は、範囲の指定は外して、それぞれの変数について、 標準化 した値でグラフを作ってみます。
df2 = (df - df.mean())/df.std() # 標準化をする
sns.heatmap(data = df2) # 標準化したデータのヒートマップを描く
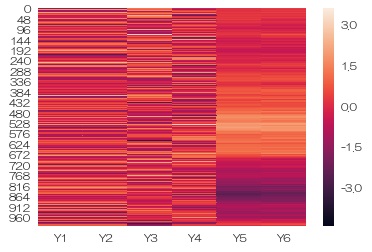
Y5とY6がほぼ同じことがもっと明確にわかっただけでなく、Y1とY2も標準化したデータでは、ほぼ同じことがわかりました。 ちなみに、Y5やY6は、色が段階的に変化していますが、こういう変数は、 自己相関 していると言えます。 他の変数は、数字の並び方がバラバラなので、自己相関していません。
たくさんの変数を見るためのグラフというのは、下のような形のデータについて、複数の列を一度に見る時になります。
データは、「Y1」、「Y2」、「Y3」、という列名の量的変数が入っていることを想定しています。 質的変数が入っていても良いですが、このグラフでは対象になりません。
なお、このグラフを作る時に、各変数のデータ数は、同じでなくても大丈夫です。 各変数の同じ行のデータが、「測定の日時が同じ」等の何かの共通点を持っている必要はないです。 逆に言えば、このタイプのグラフを作る時には、行が同じであることに意味がある場合でも、分析の対象になりません。
・・・ 共通のコード に戻る・・・
sns.stripplot(data = df) # 一次元散布図を描く
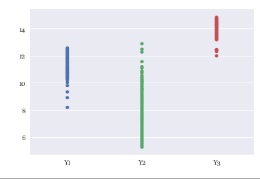
スワームプロットは、一次元散布図の仲間ですが、 データが重ならないように、左右に散らします。 一次元散布図とヒストグラムの中間のようなグラフです。
sns.swarmplot(data = df) # スワームプロットを描く
sns.boxplot(data = df) # 箱ひげ図を描く
sns.violinplot(data = df) # ヴァイオリンプロットを描く
ヴァイオリンプロットはスワームプロットと似ています。データそのものではなく、計算された分布の曲線が表されます。
筆者の場合は、生のデータのひとつひとつについて、位置を確認することが大事なテーマが多いので、
使う機会がありません。
sns.pointplot(data = df) # 信頼区間を描く
ポイントプロットは、平均値と
信頼区間
のグラフです。
平均値同士が線で結ばれていますが、これに意味があるかどうかは、データの内容によります。
全部の量的変数をグラフにする方法のうち、ヒストグラムについては、seabornではできないようなので、
PandasのPlot
を使った方が良いようです。
ただし、sns.set()を共通のコードで入れておくと、見た目はseaborn風になります。
df.plot.hist(subplots=True)# グラフを分けてヒストグラムを描く
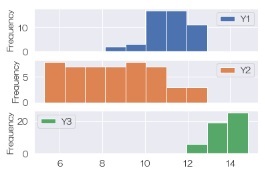
ちなみに、同じ枠の中にヒストグラムを複数入れる作り方がありますが、 煩雑でわかりにくくなりやすいので、分布が明確に分かれる場合以外は、筆者は使いません。
df.plot.hist()# ヒストグラムを描く
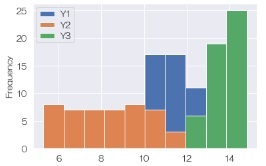
sns.lineplot(data = df) # 折れ線グラフを描く
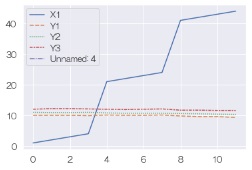
ただし、 seabornで全部の量的変数のサンプル順の折れ線グラフを作ると、全部の変数が1つの枠に入るグラフになるため、 1つの変数の動き以外はよくわからないグラフになることがあります。 こういう時の対策はseabornにはないので、 PandasのPlot を使った方が良いです。
ただし、sns.set()を共通のコードで入れておくと、
PandasのPlot
で作っても、見た目はseaborn風になります。
データは、「Y1」、「X1」、「X2」、「X3」、という列名の量的変数が入っていることを想定しています。 質的変数が入っていても良いですが、このグラフでは対象になりません。
多変量データの相関分析 のグラフを作れます。 対角線上は、それぞれの変数のヒストグラムです。
・・・ 共通のコード に戻る・・・
sns.pairplot(df) # 散布図行列を描く
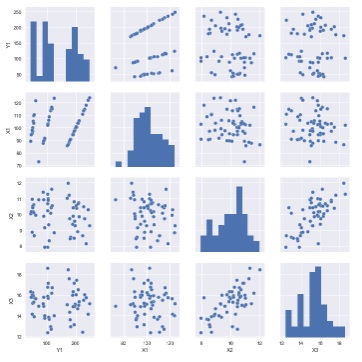
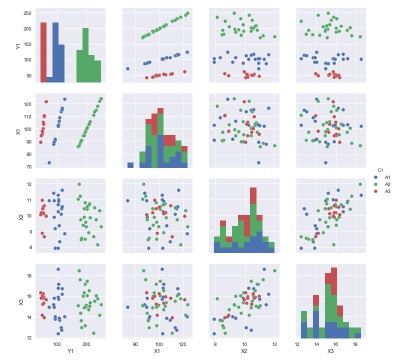
「C1」という質的変数が入っている場合、この変数で色分けすることもできます。
sns.pairplot(df, hue='C1') # 散布図行列を描く
ヒートマップ で 多変量データの相関分析 をすることもできます。
ここで使っているデータは、 全部の量的変数のヒートマップ と同じものです。
sns.heatmap(data = df.corr(), annot=True)# 相関行列を描く
データは、「Y1」、「X1」、という列名の量的変数が入っていることを想定しています。
lineplotはグラフのサイズの変更ができますが、relplotはできません。 その代わり、層別はrelplotの方ができることが多いので、探索的データ分析に向いています。
sns.lineplot(data=df, x='X1', y='Y1',marker='o') # 折れ線グラフを描く
または、
sns.relplot(data=df, x='X1', y='Y1', kind='line',marker='o') # 折れ線グラフを描く
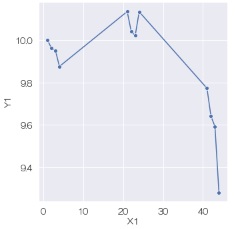
「marker='o'」がないと、プロットがなくなって線だけになります。 lineplotやrelplotで折れ線グラフを作ると、Xの値が等間隔でなければ、等間隔になりません。 等間隔ではない時は、線だけだと、プロットの位置がわからないので、プロットはあった方が良いです。
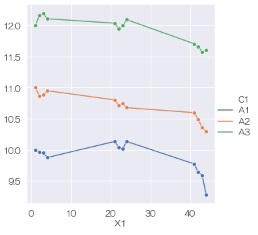
データは、「Y1」、「X1」、という列名の量的変数が入っていて、「C1」という質的変数があることを想定しています。
C1によって、色を変える折れ線グラフを作ります。
sns.lineplot(data=df, x='X1', y='Y1',marker='o',hue='C1') # 折れ線グラフを描く
または、
sns.relplot(data=df, x='X1', y='Y1', kind='line',marker='o',hue='C1') # 層別の折れ線グラフを描く
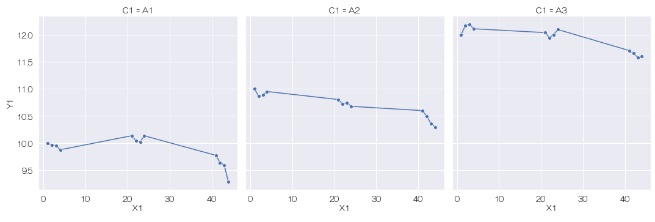
relplotでは、グラフの枠を分けて、されに層別できます。 まず、C1によって、グラフが横に分割される折れ線グラフを作ります。
sns.relplot(data=df, x='X1', y='Y1', kind='line',marker='o',col='C1') # 層別の折れ線グラフを描く
C1によって、グラフが縦に分割される折れ線グラフを作ります。
sns.relplot(data=df, x='X1', y='Y1', kind='line',marker='o',row='C1') # 層別の折れ線グラフを描く
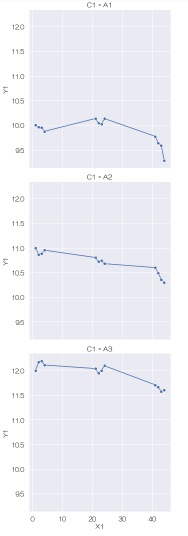
質的変数が複数ある時は、色と、縦・横の分割の3種類を使って、もっと分けることもできます。
層別のグラフを作った時のデータは、同じXが複数あるデータです。 このようなデータの場合、折れ線グラフはそれぞれのXでの平均値と 信頼区間 のグラフになります。
sns.relplot(data=df, x='X1', y='Y1', kind='line',marker='o') # 信頼区間の折れ線グラフを描く
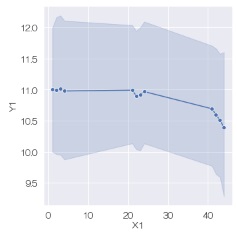
データは、「Y1」、「X1」、という列名の量的変数が入っていることを想定しています。
下記は、scatterplot、relplotとlmplotがありますが、同じものができます。 グラフのサイズ が変えられるのは、scatterplotです。
・・・ 共通のコード に戻る・・・
sns.scatterplot(data=df, x='X1', y='Y1') # 散布図を描く
または、
sns.relplot(data=df, x='X1', y='Y1',kind='scatter') # 散布図を描く
または、
sns.lmplot(data=df, x='X1', y='Y1', fit_reg=False) # 散布図を描く
「C1」、という列名の質的変数が入っていると、この変数で色分けができます。
sns.scatterplot(data=df, x='X1', y='Y1', hue='C1') # 層別散布図を描く
または、
sns.relplot(data=df, x='X1', y='Y1',kind='scatter', hue='C1') # 層別散布図を描く
または、
sns.lmplot(data=df, x='X1', y='Y1', fit_reg=False, hue='C1') # 層別散布図を描く
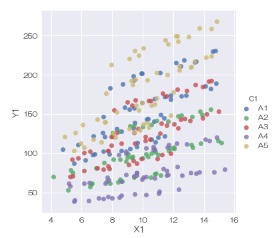
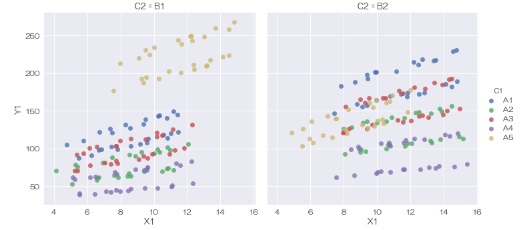
「C2」という列名で、グラフを分割することもできます。 scatterplotは枠を分けることができません。
sns.relplot(data=df, x='X1', y='Y1',kind='scatter', hue='C1', col='C2') # 層別散布図を描く
または、
sns.lmplot(data=df, x='X1', y='Y1', fit_reg=False, hue='C1', col='C2') # 層別散布図を描く
さらに「C2」と「C3」という列名で、グラフを縦横に分割することもできます。
sns.relplot(data=df, x='X1', y='Y1',kind='scatter', hue='C1', col='C3', row='C2') # 層別散布図を描く
または、
sns.lmplot(data=df, x='X1', y='Y1', fit_reg=False, hue='C1', col='C3', row='C2') # 層別散布図を描く
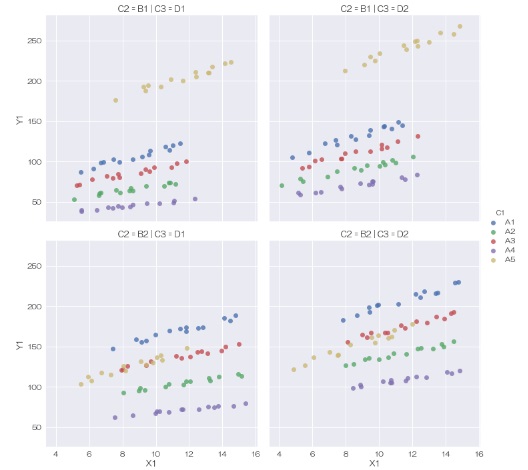
質的変数は、hue、col、rowの3種類の使い方ができます。
筆者自身は、ここまでの分解をしたことはないですが、 動特性 の実験データの分析をする時に、あると良いことが今後あるかもしれません。
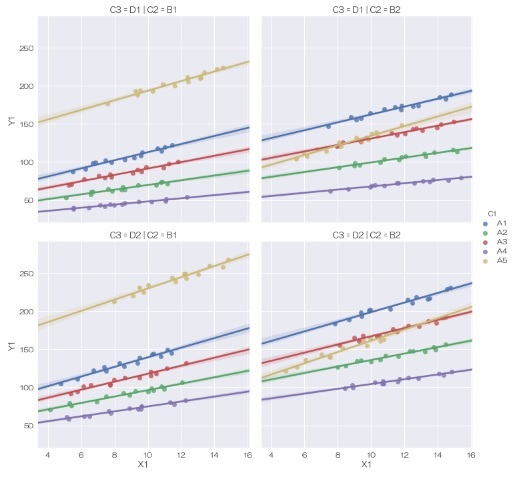
lmplotでは折れ線グラフは作れないのですが、その代わり、回帰線を描くことができます。 色や枠が分割されていれば、その分割した数だけ回帰線が計算されます。 色が薄いですが信頼区間も出ますし、引数を設定すれば、回帰線の計算方法も高度なものが使えるようになっています。
sns.lmplot(data=df, x='X1', y='Y1', hue='C1', col='C2',row='C3',fit_reg=True) # 回帰線を描く
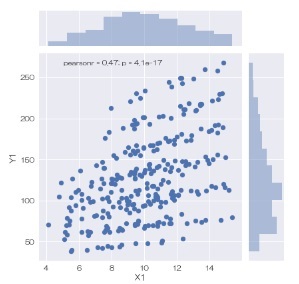
2つの変数について、散布図とヒストグラムを合体させたグラフを作ることができます。 引数を変えると、散布図を6角形の2次元ヒストグラムや等高線に変えることもできます。
sns.jointplot(data = df, x='X1', y='Y1') # ジョイントプロットを描く
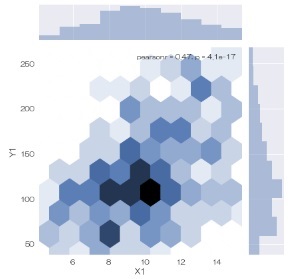
matplotlibの2次元ヒストグラム は4角形の格子の ヒートマップ ですが、seabornでは6角形の格子で作れるようになっています。
sns.jointplot(data = df, x='X1', y='Y1', kind="hex") # 6角形の2次元ヒストグラム
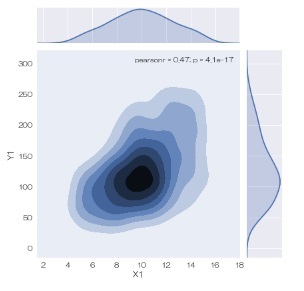
データの密度を計算して、密度の等高線を描いてくれます。
sns.jointplot(data = df, x='X1', y='Y1', kind="kde") # 密度分布を描く
同じデータについて、散布図を分解することで、回帰線がたくさん引ける(条件が絞られると相関が高くなる)関係を見つける分析を進めることもできますし、 2次元ヒストグラムや、密度分布で、データがたくさんある領域を見つける分析に進むこともできます。
ヒストグラム の作り方です。 共通のコード の後の入力になります。
この欄のヒストグラムは、
全部の量的変数の1次元分布の比較
のためではなく、
1つの量的変数の分析のためのグラフ
としての使い方です。
つまり、左のデータ形式ではなく、右のデータ形式の時の使い方です。
1つの量的変数の分析のためのグラフ
には、catplotで作れるグラフを集めているのですが、ヒストグラムはcatplotで作れないので分けました。
データは、「Y1」という列名で数値が入っていることを想定しています。
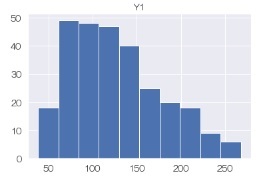
seabornでヒストグラムを作るにはdistplotがありますが、範囲の調整の使い勝手が悪いです。 下記は PandasのPlot を使っています。
df.hist('Y1') # ヒストグラムを描く
層別のヒストグラムも作れます。 データは、「C1」という列名でカテゴリ、「Y1」という列名で数値が入っていることを想定しています。
seabornのFacetGridで枠を作って、その中に、matplotlibのヒストグラムを入れる形になります。
sns.FacetGrid(df,col='C1').map(plt.hist,'Y1'))# 層別のヒストグラムを描く

さらに層別するヒストグラムも作れます。 データは、「C1」、「C2」という列名でカテゴリ、「Y1」という列名で数値が入っていることを想定しています。
2つの質的変数を縦と横の枠にして、作ります。
sns.FacetGrid(df,row='C2',col='C1').map(plt.hist,'Y1'))# 2段層別ヒストグラムを描く
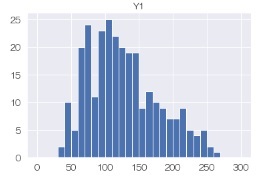
デフォルトの区間は、最大値と最小値の間を適度に等分して決まっています。 例えば、上のヒストグラムについて、0から300の範囲を30等分して、0,10,20のように区切りの良い数字にすることもできます。
df.hist('Y1',bins=30,range=(0,300))# 区切りの良い区切りのヒストグラムを描く
1つの量的変数の分析のためのグラフというのは、下のような形のデータについて、見る時になります。
データは、「Y1」という列名の量的変数が入っていていることを想定しています。
どのグラフもcatplotのものと、そうでないものがありますが、作られるグラフは同じです。 catplotだと、グラフのサイズが変えられないので、グラフを分割していくつもりがないなら、使わない方が良いです。
・・・ 共通のコード に戻る・・・
sns.stripplot(data = df, y='Y1') # 一次元散布図を描く
または、
sns.catplot(data = df, y='Y1', kind='strip', jitter=False) # 一次元散布図を描く
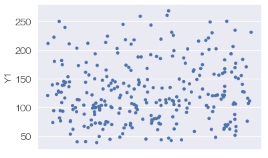
データ数が280個あるのですが、一次元散布図だと、データの密集しているところはよくわからないです。

sns.stripplot(data = df, y='Y1', jitter=True) # 一次元ジター散布図を描く
または、
sns.catplot(data = df, y='Y1', kind='strip', jitter=True) # 一次元ジター散布図を描く
2次元散布図のように見えますが、X軸方向は散らしているだけなので意味がありません。
sns.swarmplot(data = df, y='Y1') # スワームプロットを描く
または、
sns.catplot(data = df, y='Y1', kind='swarm') # スワームプロットを描く

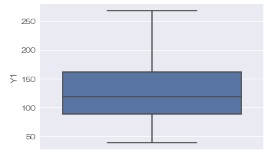
sns.boxplot(data = df, y='Y1') # 箱ひげ図を描く
または、
sns.catplot(data = df, y='Y1', kind='box') # 箱ひげ図を描く
sns.violinplot(data = df, y='Y1', inner="quartile") # ヴァイオリンプロットを描く
または、
sns.catplot(data = df, y='Y1', kind='violin', inner="quartile") # ヴァイオリンプロットを描く
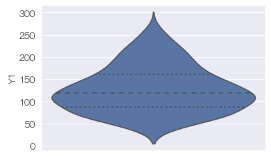
sns.pointplot(data = df, y='Y1') # 信頼区間を描く
または、
sns.catplot(data = df, y='Y1') # 信頼区間を描く

データは、「Y1」という列名の量的変数が入っていて、「C1]という列名の質的変数が入っていることを想定しています。
・・・ 共通のコード に戻る・・・
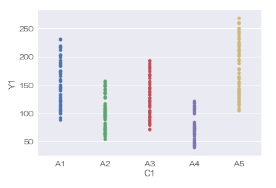
sns.stripplot(data = df, x='C1', y='Y1') # 一次元散布図を描く
または、
sns.catplot(data = df, x='C1', y='Y1', kind='strip', jitter=False) # 一次元散布図を描く
sns.stripplot(data = df, x='C1', y='Y1', jitter=True) # 一次元ジター散布図を描く
または、
sns.catplot(data = df, x='C1', y='Y1', kind='strip', jitter=True) # 一次元ジター散布図を描く
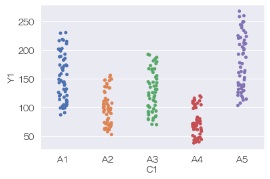
sns.swarmplot(data = df, x='C1', y='Y1') # スワームプロットを描く
または、
sns.catplot(data = df, x='C1', y='Y1', kind='swarm') # スワームプロットを描く
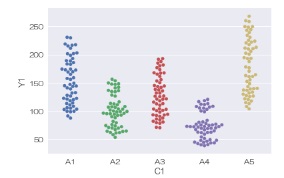
sns.boxplot(data = df, x='C1', y='Y1') # 箱ひげ図を描く
または、
sns.catplot(data = df, x='C1', y='Y1', kind='box') # 箱ひげ図を描く
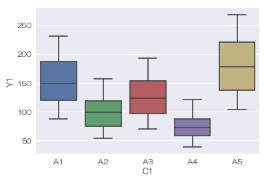
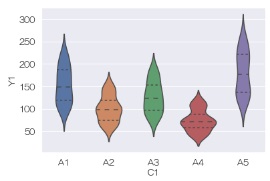
sns.violinplot(data = df, x='C1', y='Y1', inner="quartile") # ヴァイオリンプロットを描く
または、
sns.catplot(data = df, x='C1', y='Y1', kind='violin', inner="quartile") # ヴァイオリンプロットを描く
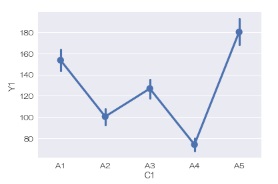
sns.pointplot(data = df, x='C1', y='Y1') # 信頼区間を描く
または、
sns.catplot(data = df, x='C1', y='Y1') # 信頼区間を描く
一元配置分散分析
とやりたいことが同じグラフです。
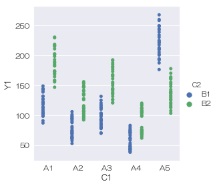
C2という質的変数もある時には、位置と色で2つの質的変数を分けることもできます。
・・・ 共通のコード に戻る・・・
sns.stripplot(data = df, x='C1', y='Y1', hue='C2', jitter=False, dodge=True) # 一次元散布図を描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2', kind='strip', jitter=False, dodge=True) # 一次元散布図を描く
sns.stripplot(data = df, x='C1', y='Y1', hue='C2', jitter=True, dodge=True) # 一次元ジター散布図を描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2', kind='strip', jitter=True, dodge=True) # 一次元ジター散布図を描く
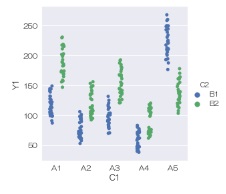
sns.swarmplot(data = df, x='C1', y='Y1', hue='C2', dodge=True) # スワームプロットを描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2', kind='swarm', dodge=True) # スワームプロットを描く
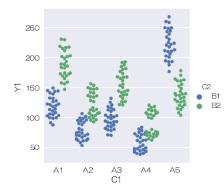
sns.boxplot(data = df, x='C1', y='Y1', hue='C2') # 箱ひげ図を描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2', kind='box') # 箱ひげ図を描く
箱ひげ図では、色分けすると、箱が横にずれるのがデフォルトなので、dodgeの指定は不要です。
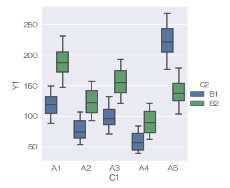
sns.violinplot(data = df, x='C1', y='Y1', hue='C2', split=True, inner="quartile") # ヴァイオリンプロットを描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2', kind='violin', split=True, inner="quartile") # ヴァイオリンプロットを描く
左右対称になって、ヴァイオリンらしい形になると、「分布が同じ」ということを表すので良いと思います。
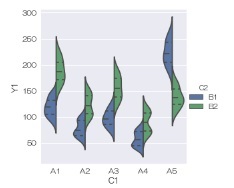
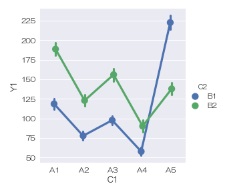
sns.pointplot(data = df, x='C1', y='Y1',hue ='C2', dodge=True) # 信頼区間を描く
または、
sns.catplot(data = df, x='C1', y='Y1',hue ='C2', dodge=True) # 信頼区間を描く
信頼区間がkindのデフォルトなので、信頼区間の時は、kindの指定が不要です。
二元配置分散分析
とやりたいことが同じグラフです。
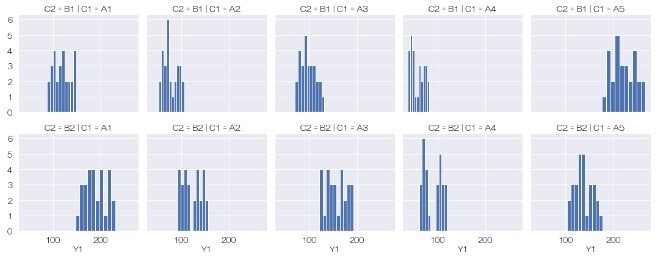
A4とA5のところで、B1とB2の上下関係が逆転していて、線が交差していますが、
実験データの解析
では、こういった交差があると、「
交互作用
がある」という見方をします。
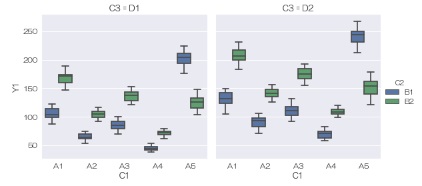
catplotでは、質的変数が3、4個の層別でもグラフの分割によって対応できます。 煩雑になるので、使用例は箱ひげ図だけにしていますが、ヒストグラム以外の他のグラフでも同じようにできます。
データは、「Y1」という列名の量的変数が入っていて、「C1」、「C2」、「C3」という列名の質的変数が入っていることを想定しています。
・・・ 共通のコード に戻る・・・
sns.catplot(data = df, x='C1', y='Y1', col='C3', hue='C2',kind='box') # 箱ひげ図を描く
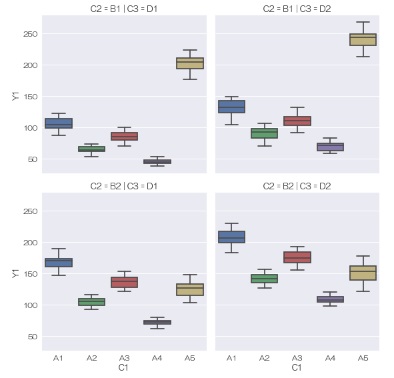
上では、色と横に分割することでグループを分けました。 色を使わずに縦・横に分割する方法もあります。
sns.catplot(data = df, x='C1', y='Y1', col='C3', row='C2',kind='box') # 箱ひげ図を描く
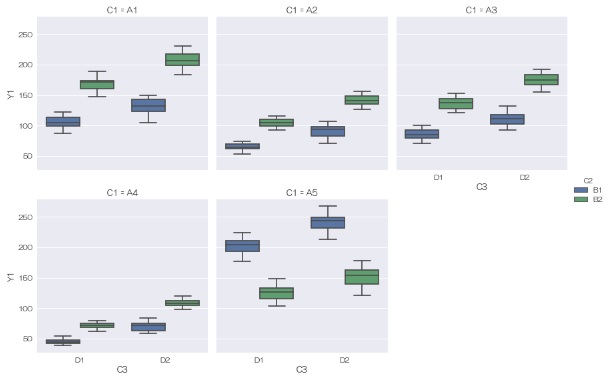
catplotを使うと、質的変数は、x、hue、col、rowの4種類の使い方ができます。 グラフの種類と、これらの組み合わせで、いろいろな作り方ができます。 全部使えば、1つの量的変数を4つの質的変数で分解するグラフも作れます。(作ったグラフを理解するのは大変かもしれませんが)
catplotを使うと、グラフのサイズ変更ができないです。 探索的なデータ分析の時は、不便さは感じないかもしれませんが、大きさを調整したい場合は、 catplotを使わなくても、x、hueの2種類は使える方法があることを活用した方が良いです。
ここで使っているデータで、colにC1を指定すると、枠が5個横に並びます。 5個くらいなら良いかもしれませんが、数が増えて来ると、横並びはきびしくなります。
sns.catplot(data = df, x='C3', y='Y1', col='C1', hue='C2',kind='box') # 箱ひげ図を描く

「col_wrap」という引数で横に並べる数を指定することで、無理に横並びにしないで済むようにもできます。
sns.catplot(data = df, x='C3', y='Y1', col='C1', hue='C2',kind='box',col_wrap = 3) # 箱ひげ図を描く
上記で使ったcatplotには 棒グラフ を作る機能もあります。 下の例は、簡単なものですが、質的変数を4つまで設定して分類できるところは、上記と同じです。
・・・ 共通のコード に戻る・・・
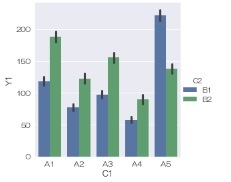
sns.barplot(data = df, x='C1', y='Y1', hue='C2') # 普通の棒グラフを描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2',kind='bar') # 普通の棒グラフを描く
「bar」で棒グラフを作る時に、同じカテゴリのデータが複数あると、棒の長さがそれらの平均値になり、 信頼区間がヒゲで表されるようになっています。
データが「長さ」に関係があるものだと、棒グラフによる表現は直接的で良いと思うのですが、 筆者の場合は、使う機会がありません。
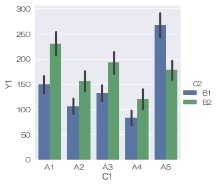
sns.barplot(data = df, x='C1', y='Y1', hue='C2') # 平均値と信頼区間の棒グラフ描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2', kind='bar') # 平均値と信頼区間の棒グラフ描く
ヒゲを標準偏差、棒の長さを最大値に変えるのでしたら、下のようになります。
sns.barplot(data = df, x='C1', y='Y1', hue='C2', ci='sd', estimator=max) # 最大値と標準偏差の棒グラフ描く
または、
sns.catplot(data = df, x='C1', y='Y1', hue='C2', kind='bar', ci='sd', estimator=max) # 最大値と標準偏差の棒グラフ描く
「ci = 95」と書くと95%の信頼区間になり、任意の数字を設定することができます。 公式ページにデフォルトの値が書いていないのですが、95のようです。
データは、「C1」、「C2」という質的変数が入っていていることを想定しています。 ソフトがデータの数(頻度)を自動的に数えてくれる機能を使って、棒グラフを作ることもできます。 分割表 や 混同行列 による分析と組み合わせることができます。
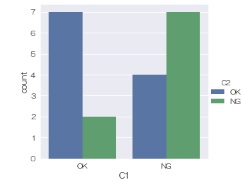
このページには一般的な1次元のヒストグラムの他に、 2次元のヒストグラム がありますが、そういう見方をすると、 ここにある頻度のグラフは、0次元の層別ヒストグラムと考えることができます。
sns.countplot(data = df, x='C1', hue='C2') # 頻度グラフを描く
または、
sns.catplot(data = df, x='C1', hue='C2',kind='count') # 頻度グラフを描く
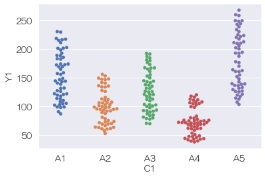
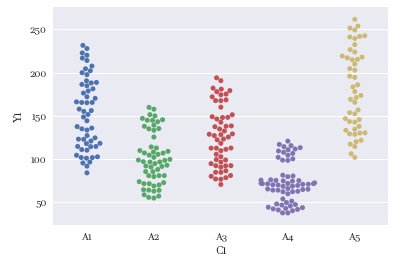
グラフのサイズですが、左がデフォルトで、右が下のコードでサイズを調整したものです。 グラフを描く行の前に、サイズ調整の行を入れます。
plt.figure(figsize=(3,3)) # グラフのサイズを変える
sns.swarmplot(data = df, x='C1', y='Y1') # スワームプロットを描く
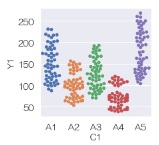
このページの方法の中でも、「df.」で始まるPandasのPlotについては、これではなく、 PandasのPlotのグラフのサイズ にまとめました。
これらのコードですが、pairplot、jointplot、catplotのように枠を複数使うようになっているものは、ダメなようです。 matplotlibの根本的な仕様までさかのぼってコードを作れば、対応できるようなのですが、 筆者としては実用的でないので、手をつけていません。
デフォルトのサイズで困る場合は、グラフの分割が多過ぎて、ひとつひとつがつぶれてしまう場合です。 サイズの変更ができたとしても、1画面に収まらなかったり、 情報量が多過ぎて、人に説明するグラフとしては良くなかったりもします。 このような時は、サイズ変更で解決するよりも、2段階にして グラフにするデータをあらかじめ検討して、データを絞ってからグラフにする方が現実的な対策になっています。 事前に、 データの切り貼り をします。
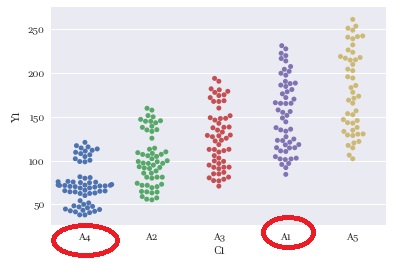
上のグラフでは、グラフを作る前に、質的変数については名前順になるようにデータを並べ替えています。
そうすることで、左のグラフのように、左から名前順になっています。
データの前処理をしないと、上にあるデータの名前の順にグラフも並びます。
必ずしも前処理は必要ではありませんが、グラフを見る時には注意が必要です。
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
df= pd.read_csv("Data.csv" , engine='python')# PandasのPlotのグラフの見た目をseaborn風にする。
上は、
共通のコード
の中の2行です。こうすることで、筆者のPCでは日本語がグラフに表示できるようになります。
seabornでサイトを調べると、
sns.set()
df= pd.read_csv("Data.csv")
となっていることがあるのですが、
この書き方でも文字化けしないようにするのでしたら、PC内部の設定を修正する必要があるようです。
このサイトのコードは、 1行目は、グラフに日本語を書けるようにするために、日本語のフォントを指定しています。 2行目は、データを読み込みの時に、日本語(全角文字)でも読み込めるようにするための命令が含まれています。 1行目でこの設定を省略すると、デフォルトの設定になるため、日本語が文字化けするようになります。 2行目で省略すると、ファイルの読み込みで日本語が読み込めずにエラーになります。
日本語のフォントは、下記のコードを入力して、自分のPCの中のフォントを洗い出して、その中から日本語っぽいフォントを見つけました。 筆者のPCの場合は、このフォントがあったから良かったです。 「seaborn 文字化け」で検索すれば、記事はたくさんありますので、このサイトのコードで文字化けする場合は、調べてみてください。
import matplotlib.font_manager
print([f.name for f in matplotlib.font_manager.fontManager.ttflist])
筆者の場合、lineplot、relplot、catplot等を最初に使おうとした時に、これらが使えませんでした。
print(sns.__version__)
で、バージョンを調べたところ、0.8.0でした。
このページは、0.10.0で作っています。
Anaconda Promptで
pip install seaborn -U
で、アップデートしたら、アップデートできて使えるようになりました。
「-U」を付けないと、アップデートにならないことも知りました。
seabornの解説は数え切れないほどありますが、筆者が参考にさせていただいたページになります。
https://seaborn.pydata.org/index.html
seabornの本家のページのようです。
英語ですが、簡単なコードとグラフが並べて書いてあるページもあるので、英語が苦手でも欲しい情報が取れると思います。
引数の細かな話は、ここが一番詳しいです。
https://blog.amedama.jp/entry/seaborn-plot
多くのグラフを紹介を紹介しています。
https://pythondatascience.plavox.info/seaborn/%E6%95%A3%E5%B8%83%E5%9B%B3%E3%83%BB%E5%9B%9E%E5%B8%B0%E3%83%A2%E3%83%87%E3%83%AB
lmplotの多くの解説は、いろいろな回帰線が描けることの説明になっています。
この文献には、それも詳しく書いてあるのですが、回帰線を書き込まない設定方法もあります。
https://qiita.com/greenteabiscuit/items/2d39a5ebdaf9a136fb01
factorplotは、もうすぐ使えなくなるそうです。この文献はcatplotの説明になっています。
https://qiita.com/keisuke-nakata/items/2309764d21438645f6b9
seabornのグラフの文字化けについて、2つの対策を説明しています。
https://own-search-and-study.xyz/2015/09/03/pandas%E3%81%AEread_csv%E3%81%AE%E5%85%A8%E5%BC%95%E6%95%B0%E3%82%92%E4%BD%BF%E3%81%84%E3%81%93%E3%81%AA%E3%81%99/
Pandaによるcsv読み込みの全引数の説明の中で、engineを「python」にする説明があります。
順路
 次は
層別のグラフ
次は
層別のグラフ
 Tweet
Tweet
