 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
因子分析は、「データとして持っていないもの」について、データ解析をします。 多変量解析 の中でも、この点が際立った特徴になっています。
また、「因子分析」の名前によく表れていますが、 「原因を探る方法」や、「仮説を検証する方法」に特化しています。 多くのデータ解析は、予測や 判別 の方法として紹介される事が多いので、この点も特徴です。
因子分析は、潜在変数を使うところが、他の 多変量解析 の手法と大きく違います。
因子分析は、もともと心理学で考案されて来たものだそうです。 その段階では、潜在変数は「因子」を表現するものとして使われて来たようですが、 現在では、必ずしも因子を表すものではないです。
潜在変数は、データは持っていないけれども、データを持っている変数と関係がある変数です。 ここでは、データのある変数を、「顕在変数」と呼んでおきます。
数式としては、それぞれの顕在変数は、潜在変数の 線形和 で表します。
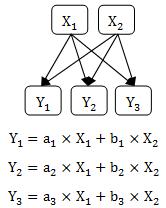 比較的古い文献に載っている因子分析は、現在は、「探索的因子分析」と呼ばれています。
比較的古い文献に載っている因子分析は、現在は、「探索的因子分析」と呼ばれています。
探索的因子分析、主成分分析、独立成分分析は、とても似ています。
主成分分析では、「分散の最大化」と、「主成分同士は無相関」というルールがあるので、自動的に線形和の係数が求まります。 分析者が介入するところがないです。
因子分析は、軸の回転方法がいろいろあるので、分析者が目的に合わせて使い分ける必要があります。
因子分析や、独立成分分析では、試行錯誤しないと、因子や独立成分の数を決められません。
主成分分析をすると、例えば、「10個の変数の値は、2つの主成分でほぼ説明できる。」、という事がわかります。 そこで、主成分分析を先に実行して、因子や独立成分の数の目安を見つけると効率的です。
主成分分析は、「データを要約するとこうなる」という分析です。 そのため、要約した結果を使って、分析は次の段階になります。 前に進む感じの分析です。
一方、因子分析や独立成分分析は、「このデータの背後や、このデータの元はこういうもの」という分析です。 後ろを振り返る感じの分析です。
同じデータに対して、因子分析、主成分分析です。
因子分析

主成分分析

因子分析では、0にならないはずのところが0になってしまうことが起きますが、 主成分分析では、「0になるはず」と思いたいところが、0に近い値にもならないということが起きます。
こうしたことからも、主成分分析は、データを因子に分解する目的には向かないことがわかります。
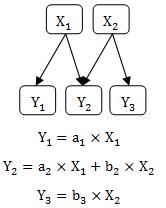 「潜在変数同士は無相関」と、「線形和にすべての潜在変数を含む」という条件を除いて、モデルを作ると、
検証的因子分析と呼ばれます。
「潜在変数同士は無相関」と、「線形和にすべての潜在変数を含む」という条件を除いて、モデルを作ると、
検証的因子分析と呼ばれます。
因子分析では、顕在変数と潜在変数で、2つの階層があります。
顕在変数と潜在変数に、もっと複雑な関係がある時のモデルを分析する方法として、 共分散構造分析 があります。
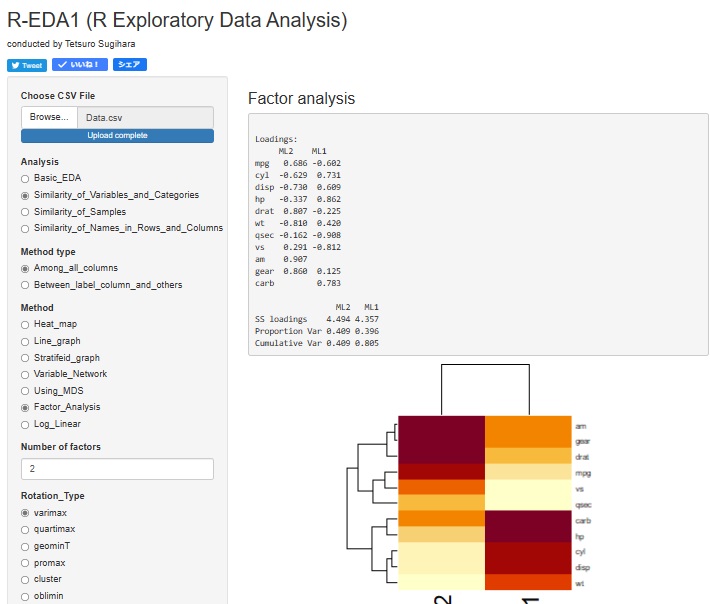
Rの実施例は、 Rによる因子分析 のページがあります。
変数と因子の関係の分析の他に、サンプルと因子の関係の分析も紹介しています。
R-EDA1の場合は、
「Similarity_of_Variables_and_Categories」
→「Among_all_columns」
→「Factor_Analysis」
と選んで行くと因子分析ができます。
因子数(Number of factors)を入力して、回転の種類(Rotation_Type)を選びます。
「ようこそ「多変量解析」クラブへ」 小野田博一 著 講談社 2014
因子分析では、因子負荷量が求まりますが、因子負荷量とその転置行列の積の非対角要素が、元の変数による相関行列と一致するようになっていることから説明されています。
対角要素の値が、各変数との共通性で、この値を1から引いた値が、この変数の独自性です。
因子分析のアルゴリズムには、いろいろありますが、相関行列の非対角要素との関係はどれも同じで、違いが出てくるのは対角要素になっています。
「図解でわかる多変量解析」 涌井良幸・涌井貞美 著 日本実業出版社 2001
この本では、探索的因子分析を解説しています。
「多変量解析法入門」 永田靖・棟近雅彦 共著 サイエンス社 2001
因子分析の結果の多くは、主成分分析の結果と一致するそうです。
「よくわかる多変量解析の基本と仕組み 巨大データベースの分析手法入門」 山口和範、高橋淳一、竹内光悦 著 秀和システム 2004
探索的因子モデルから、検証的因子モデルまでをコンパクトに解説。
「図解でわかる共分散構造分析 データから「真の原因」を探り出す新しい統計分析ツール」 涌井良幸、涌井貞美 著 日本実業出版社 2003
検証的因子分析モデルを、「確認的因子モデル」と読んでいます。
共分散構造分析の特徴や使い方を、まず、検証的因子分析モデルで解説しています。
その後で、共分散構造分析は、検証的因子分析モデル以外にも使える事を解説しています。
順路
 次は
分解分析の違い
次は
分解分析の違い
