 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
外れ値や欠損値のあるデータの解析 のページには、 欠損値 のあるデータの扱い方がありますが、このページはRを使う場合の、もっと具体的な話になります。
まず、欠損値がどのような形でデータの中にあって、それをRの中ではどのように扱っているのかです。
下のように、欠損値が文字通り、欠損していて空白になっている場合と、欠損値が「NA」という文字列になっている場合があります。
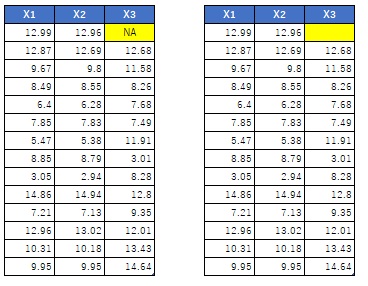
いずれも、Rに読み込むと「NA」になります。
summaryで見ると「NA's :1」となっていて、欠損値(NA)として認識されていることがわかります。
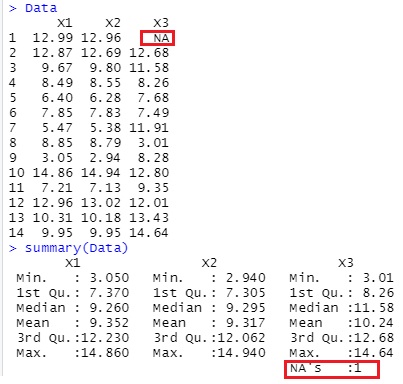
例外があるかもしれませんが、Rの場合、欠損値が含まれている量的変数に対して、何か処理をしようとすると特別な扱いになります。
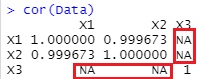
例えば、相関行列を求めると、欠損値が含まれている量的変数との相関係数は「NA」となり、求まりません。
このため、欠損値以外の数値を使うと、相関が高くてもわからないです。
ちなみに、他のソフトだと、欠損値以外の数値を使った相関係数が求まるようになっていることもあります。
欠損値をどのように変換するかで、分析できることが変わります。
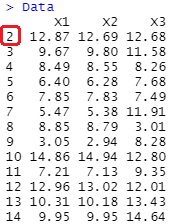
欠損値がある行は除いてしまう場合です。
欠損していることに特に意味がない場合は、手軽な方法です。 ただし、この方法で予測モデルを作った場合、予測したい段階のデータの欠損値が含まれていると、予測ができないです。
Data <- na.omit(Data)
とすると、下記になります。
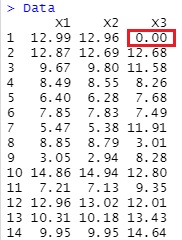
欠損値ができた背景や、欠損値の扱い方の方針によりますが、例えば、欠損値を「0」として扱いたい場合です。
Data[is.na(Data)] <- 0
とすると、下記になります。
各変数の欠損値を、その変数の、欠損値以外の数値の平均値にしたい場合は、下記になります。
for (i in 1:ncol(Data)) {
Data[,i][is.na(Data[,i])] <- mean(Data[,i], na.rm = TRUE)
}
とすると、下記になります。

質的変数の欠損値は、「NoData」という名前のカテゴリになります。 量的変数については、まず、 1次元クラスタリング をして、質的変数にします。 その後で、欠損値の部分を、「NoData」という名前のカテゴリにします。
例えば、
for (i in 1:ncol(Data)) {
if (class(Data[,i]) == "numeric"|| class(Data[,i]) == "integer") {
Data[,i] <- droplevels(cut(Data[,i], breaks = 3,include.lowest = TRUE))
Data[,i] <- factor(ifelse(is.na(Data[,i]), "NoData", as.character(Data[,i])))
}
}
Data[Data == ""] <- "NoData"
とすると、下記になります。
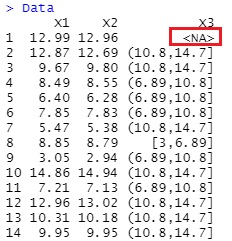
質的変数の欠損値は、「is.na」で検出されないです。「空白のセルを『NoData』にする」という意味のコードで、変換できます。
droplevelsを使って、1次元クラスタリングをすると、factor型になります。 また、欠損値は、特殊な扱いになっています。 「factor型のレベルを1つ増やして、その名前を『NoData』にして、欠損値を充当する」という意味のコードで、変換しています。
欠損値になっている理由を、他の変数から推測するための変換です。
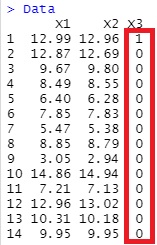
Data[,3][!is.na(Data[,3])] <- 0
Data[,3][is.na(Data[,3])] <- 1
とすると、下記になります。
こうなっていると、欠損値のある変数を
ラベル分類
の手法の目的変数にして、欠損しているかどうかと、他の変数の関係を調べることができます。
ラベル分類 によっては、目的変数が数値ではできないことがありますが、その場合、例えば、上記の「0」・「1」を、「A」・「B」とします。
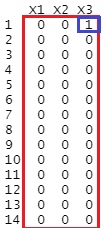
データの中に、欠損値がどこにどのように入っているのかを調べたい時の方法です。 全部の変数について、欠損値ならば1、欠損値以外は0にします。
Data[!is.na(Data)] <- 0
Data[is.na(Data)] <- 1
とすると、下記になります。
biostatistics
置換や削除について、上記以外のコードも紹介しています。
https://stats.biopapyrus.jp/r/basic/nan.html
