 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
項目反応理論 のRによる実施例です。
モデル式の係数を調べる方法です。
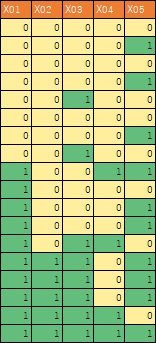
ここでは、以下のデータを使っています。
このデータのcsvファイルが、CドライブのRtestというフォルダにあることを想定しています。
setwd("C:/Rtest")
library(ltm)
Data <- read.csv("Data.csv", header=T)
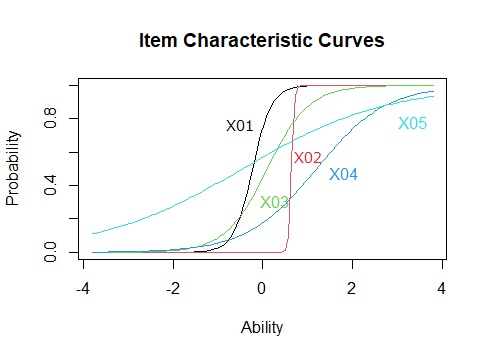
ltmModel <- ltm(Data ~ z1)
plot(ltmModel)
ここで
ltmModel <- ltm(Data ~ z1+z2)
とすると、潜在変数が2つできます。
このライブラリでは、3つ以上(z3など)は設定できないです。
ここで
ltmModel <- ltm(Data ~ z1*z2)
とすると、z1とz2の交互作用項も出ます。
上記のグラフは、変数が多いと、ごちゃごちゃして来ます。
ロジスティック関数の2つの係数で散布図にした方が、各変数の考察をしやすいです。
曲線と散布図を見比べると、係数の意味がわかります。
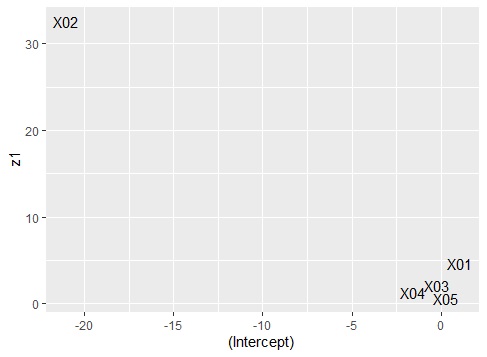
Data2 <- as.data.frame(ltmModel$coefficients)
library(ggplot2)
ggplot(Data2, aes(x=Data2[,1], y=Data2[,2],label=row.names(Data2))) + geom_text() +xlab("(Intercept) ")+ylab("z1")
サンプルの得点を調べる方法です。
Data3<-factor.scores(ltmModel)
Data3$score.dat
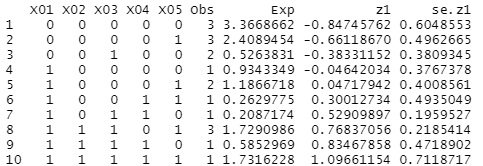
サンプルの得点は、「z1」という変数になります。正解(1)が多いほど、得点が高い様子がわかります
「obs」という変数が、同じデータのサンプルの数を表しています。 このライブラリだと、同じデータのサンプルでまとめるため、「元のデータの5番目の得点は?」という考察には不便です。 解決方法は調べてみたのですが、今のところ、わからないでいます。
setwd("C:/Rtest")
library(ltm)
Data <- read.csv("Data.csv", header=T)
ltmModel <- grm(Data)
plot(ltmModel)
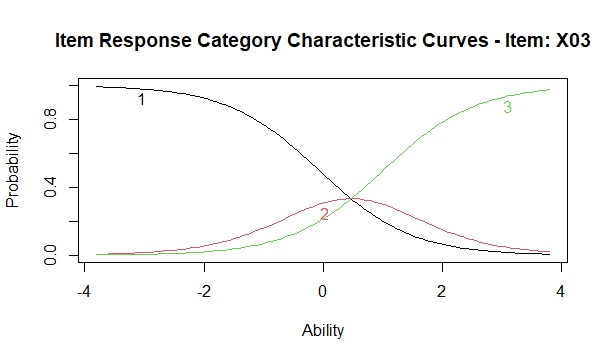
段階反応モデルでは、1変数ごとにグラフができます。
これ以降の分析は、上記の二値の時と同じコードでできます。
CRAN
https://cran.r-project.org/web/packages/ltm/ltm.pdf
ltmのマニュアルです。
Rで項目反応理論
http://www.okadajp.org/RWiki/?R%E3%81%A7%E9%A0%85%E7%9B%AE%E5%8F%8D%E5%BF%9C%E7%90%86%E8%AB%96
ltmの簡単な使用例があります。
項目反応理論(1):ltmパッケージで段階反応モデル
https://researchmap.jp/blogs/blog_entries/view/81322/62c39d2eb774957c3d44b18cb7aaa4c5?frame_id=587187
段階反応モデルで進め方があります。
